Для выполнения на компьютере какой-либо программы необходимо, чтобы она имела доступ к ресурсам компьютера
| Вид материала | Документы |
- Операционная система компьютера (назначение, состав, загрузка) Назначение, 99.73kb.
- Невырожденные матрицы обратная матрица, 27.2kb.
- Пример настоящей программы для компьютера на языке Лого 16 > Последовательность работы, 4798.61kb.
- Автор программы И. В. Баркова Ф. И. О., Педагога дополнительного образования; квалификационная, 224.25kb.
- Назначение и состав операционной системы компьютера. Загрузка компьютера, 95.4kb.
- Все программы и данные хранятся в долговременной (внешней) памяти компьютера в виде, 91.55kb.
- 1. Введение Ни одна страна, какой бы крупной и самообеспеченной важнейшими ресурсами, 1012.34kb.
- Белая Холуница Кировская область Описание проекта Название проекта Алгоритмы и основы, 179.54kb.
- Реферат «Защита информации» Ученица 9 класса Гагарина Надежда Руководитель элек- тивного, 55.96kb.
- Языки программирования, 27.65kb.
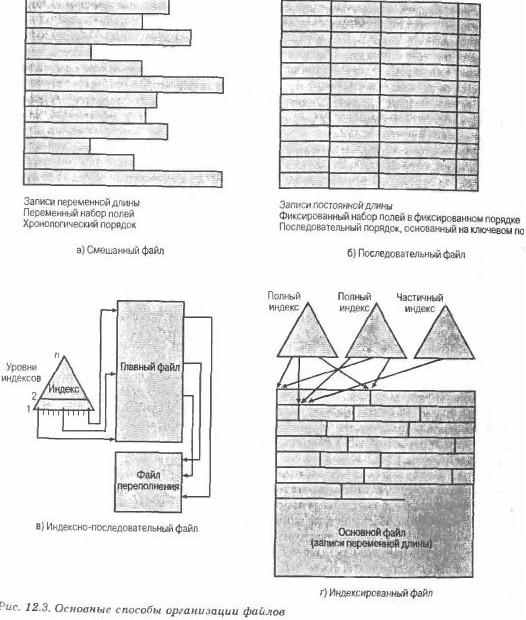
Последовательный файл.
Для записей используется фиксированный формат. Все записи имеют одинаковую длину и состоят из одинакового количества полей фиксированной длины, организованных в определенном порядке. Поскольку длина и позиция каждого поля известны, то сохранению подлежат только значения полей; атрибутами файловой структуры являются имя и длина каждого поля. Одно определённое поле, обычно – первое поле в каждой записи, называется ключевым полем, которое идентифицирует запись уникальным образом, так что ключевые значения различных записей всегда различны. Более того, записи сохраняются в «ключевой» последовательности: в алфавитном порядке для текстового ключа и числовом порядке для числового ключа.
Последовательные файлы часто используются пакетными приложениями и обычно являются оптимальным вариантом, если эти приложения выполняют обработку всех записей. Для диалоговых приложений, которые работают с запросами и/или выполняют обновление индивидуальных записей, последовательный файл является малоэффективным. Дополнения к файлу так же создают проблемы. Обычно последовательный файл сохраняется с последовательной организацией записей внутри блоков. Другими словами, физическая организация файла на диске в точности соответствует логической организации файла. В этом случае обычно выполняется размещение новых записей в отдельном смешанном файле, называемом журнальным файлом или файлом транзакции. Периодически в пакетном режиме выполняется слияние нового и журнального файлов в новый файл с корректной последовательностью ключей.
Альтернативной организацией может служить физическая организация последовательного файла в виде списка с использованием указателей. В каждом физическом блоке сохраняется одно или несколько записей. Каждый блок на диске содержит указатель на следующий блок. Для вставки новых записей достаточно изменить указатели, и нет необходимости в том, чтобы новые записи занимали определённую физическую позицию. Это удобство достигается за счёт определённых накладных расходов и дополнительной работы.
Индексно-последовательный файл.
Индексно-последовательный файл сохраняет главную особенность последовательного файла: записи организованы последовательно на основании значений ключевого поля. Но при описываемой организации добавлены две особенности: индекс файла для поддержки произвольного доступа и файл (или область) переполнения. Индекс обеспечивает возможность быстрого поиска требуемой записи. Файл переполнения подобен журнальному файлу, используемому файлом последовательного доступа, однако организован таким образом, что записи в нём размещаются, следуя указателю предшествующей записи.
В простейшей индексировано-последовательной структуре используется единственный уровень индексации, и индекс в этом случае представляет собой простой последовательный файл. Каждая запись в индексном файле состоит из двух полей: ключевого поля, идентичного ключевому полю в основном файле, и указателя в основной файл с ключами. Для обнаружения определённого поля сперва выполняется поиск в индексном файле. После того как в нём найдено наибольшее значение ключа, которое не превышает искомое, продолжается поиск в основном файле в позиции, определённой указателем из индексного файла.
Дополнения к файлу обрабатываются следующим образом. В каждой записи главного файла содержится дополнительное поле, невидимое для приложения и являющееся указателем на файл переполнения. Если в файл производится вставка новой записи, она добавляется в файл переполнения. Запись в главном файле, непосредственно предшествующая новой записи в логической последовательности, обновляется и указывает на новую запись в файле переполнения. Если запись, непосредственно предшествующая новой, сама оказывается в файле переполнения, то обновляется указатель этой записи. Как и в случае с последовательным файлом, время от времени выполняется слияние индексно-последовательного файла с файлом переполнения.
Индексно-последовательная организация намного сокращает время, необходимое для доступа к записи, не изменяя при этом последовательную природу файла. Для последовательной обработки всего файла записи в главном файле обрабатываются до тех пор, пока не встретится нулевой указатель, свидетельствующий о завершении цепочки. Затем продолжится обработка записей основного файла с того места, на котором произошло обращение к файлу переполнения. Для обеспечения общей производительности при обращениях может использоваться многоуровневая индексация. При этом нижний уровень индексного файла рассматривается как последовательный файл, для которого создаётся индексный файл верхнего уровня.
Индексированный файл.
Для достижения гибкости необходимо использование большего количества индексов, по одному для каждого типа поля, которое может быть объектом поиска. В обобщённом индексированном файле доступ к записям осуществляется только по их индексам. В результате в размещении записей нет никаких ограничений до тех пор, пока указатель по крайней мере в одном индексе ссылается на эту запись. Кроме того, в таком файле легко реализуются файлы переменной длины.
Используется два типа индексов. Полный индекс содержит по одному элементу для каждой записи главного файла. Сам по себе индекс организовывается в виде последовательного файла для облегчения поиска. Частный индекс содержит элементы для записей, в которых имеется интересующее нас поле. При добавлении новой записи в главный файл необходимо обновлять все индексные файлы.
Индексированные файлы используются прежде всего теми приложениями, в которых время доступа к информации является критической характеристикой и редко требуется обработка всех записей в файле.
Файл прямого доступа.
Файл прямого доступа, или хешированный файл, использует возможность прямого доступа к блоку с известным адресом при хранении файлов на диске. Как в последовательных файлах и файлах индексно-последовательного доступа, в каждой записи должно иметься ключевое поле. Однако концепция последовательного размещения данных здесь не используется.
Файл прямого доступа применяет хеширование ключевых значений. Файлы прямого доступа используются, когда необходим очень быстрый доступ, при записях фиксированной длины, а также в случаях, когда доступ осуществляется ко всем записям.
45. Управление файлами в ОС семейства Unix.
Ядро системы Unix рассматривает файлы как потоки (последовательности) байтов. Любая внутренняя логическая структура файлов связана с конкретными приложениями. Unix работает с физической структурой файлов.
Различают четыре вида файлов:
1. Обычные – файлы, содержащие информацию, введённую пользователем, прикладной программой или системной утилитой.
2. Каталоги – содержат списки имён файлов и указатели на индексные узлы (index node – inode). Каталоги имеют иерархическую структуру. Каталоги файлов представляют собой обычные файлы, обладающие особыми привилегиями защиты от записи, так что запись в них может произвести только файловая система, в то время как программам пользователя разрешён доступ для чтения.
3. Специальные – используются для доступа к периферийным устройствам, таким, как терминалы или принтеры. Каждое устройство ввода/вывода связано с определённым файлом.
4. Именованные – именованные каналы.
Управление всеми типами файлов ОС Unix осуществляется посредством индексных узлов (inode). Узел является управляющей структурой, содержащей ключевую информацию, необходимую операционный системе для работы с определённым файлом. С одним узлом может быть связано несколько имён файлов, однако активный узел связан исключительно с одним файлом, и каждый файл управляется исключительно одним узлом. В узле сохраняются атрибуты файла и права доступа к нему, а так же другая управляющая информация.
Размещение файлов выполняется поблочно, динамически, по мере необходимости. Следовательно, блоки файла на диске необязательно образуют непрерывную область. Для отслеживания файла используется индексный метод; часть индекса хранится в узле файла. Узел включает 39 байт адресной информации, организованной как 13 3-байтовых адресов, или указателей. Первые 10 адресов указывают на первые 10 блоков данных файла. Если файл длиннее 10 блоков, то используется один или несколько уровней косвенности:
- Одиннадцатый адрес узла указывает на блок на диске (блок первого уровня косвенности), содержащий следующую часть индекса. Этот блок содержит указатели на последующие блоки файла.
- Если файл содержит ещё большее количество блоков, то двенадцатый адрес узла укажет блок второго уровня косвенности. Этот блок содержит список адресов дополнительных блоков первого уровня косвенности. В свою очередь, каждый из них содержит указатели на файловые блоки.
- Если файл содержит ещё больше блоков, для которых не хватает косвенности второго уровня, то тринадцатый адрес в узле указывает на блок третьего уровня косвенности. Этот блок указывает на дополнительные косвенные блоки второго уровня.
Уровень | Количество блоков | Количество байтов |
Прямой | 10 | 10Кбайт |
Один уровень косвенности | 256 | 256Кбайт |
Два уровня косвенности | 265х256=65К | 65Мбайт |
Три уровня косвенности | 256х65К=16М | 16Гбайт |
Общее количество блоков данных в файле зависит от ёмкости блоков фиксированного объёма в системе. В Unix System V длина блоков равна 1 Кбайт, и каждый блок может содержать до 256 адресов блоков. Следовательно, максимальный размер файла в этой схеме превышает 16 Гбайт.
Такая схема обладает рядом преимуществ:
1. Узел имеет фиксированный относительно небольшой размер и потому может длительное время содержаться в основной памяти.
2. Доступ к небольшим файлам осуществляется с малым уровнем косвенности (или и вовсе без него), что сокращает время обработки запроса и доступа к диску.
3. Теоретический максимальный размер файла достаточно велик для удовлетворения практически всех приложений.
46. Управление файлами в ОС семейства Windows.
Файловая система Windows NT – NTFS.
Особенности NTFS:
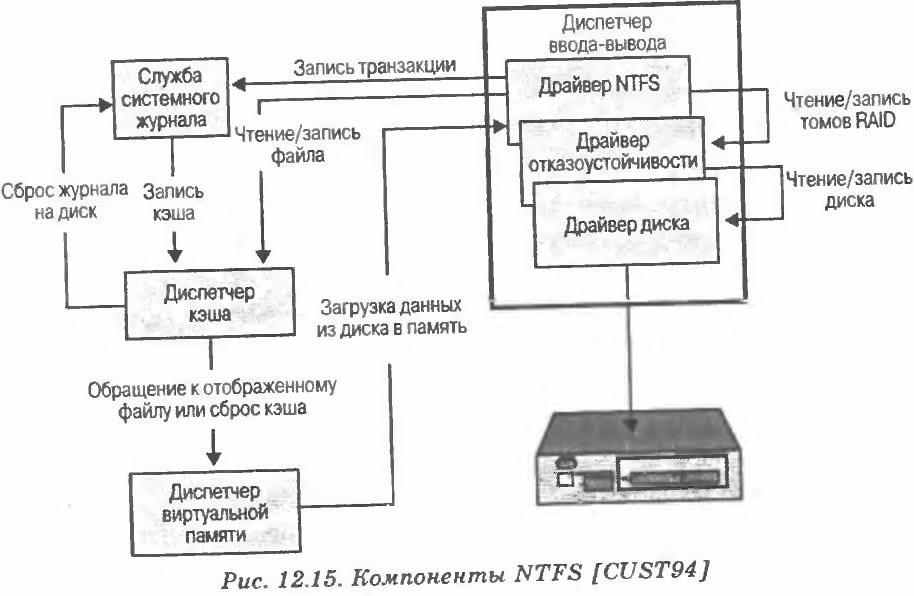
- Способность восстановления данных. При полном отказе системы и сбоях дисков система NTFS способна реконструировать дисковые тома и вернуть их к согласованному состоянию. Это достигается посредством использования модели обработки транзакций для операций обмена в файловой системе; каждый значительный обмен рассматривается как атомарное действие, которое либо выполняется полностью, либо не выполняется вовсе. Кроме того, NTFS использует избыточное хранение избыточных данных файловой системы.
- Безопасность. Для обеспечения безопасности NTFS использует объектную модель W2K (Windows 2000). Открытый файл реализуется как файловый объект с дескриптором, определяющим атрибуты безопасности.
- Диски и файлы больших объёмов. NTFS поддерживает очень большие диски и файлы более эффективно по сравнению с другими файловыми системами, включая FAT.
- Множественные потоки данных. Содержимое файла рассматривается как поток байтов. В NTFS можно определить несколько потоков данных для одного файла. Примером использования для этой особенности служит использование W2K удалёнными системами Macintosh для хранения и получения файлов. В компьютерах Macintosh каждый файл состоит из двух компонентов: данных файла и ветви ресурса, которая содержит информацию о файле. NTFS рассматривает эти компоненты как два потока данных.
- Обобщённая индексация. NTFS связывает с каждым файлом набор атрибутов. Набор описаний файлов в системе управления файлами организован как реляционная база данных, поэтому файлы могут быть индексированы по любому атрибуту.
NTFS использует следующие концепции дискового хранения:
- Сектор. Наименьшая единица физического хранения на диске. Размер данных в байтах является степенью двойки и почти всегда равен 512 байт.
- Кластер. Один или несколько последовательных секторов на одной дорожке. Размер кластера в секторах является степенью двойки.
- Том. Логический раздел диска, состоящий из некоторого количества кластеров и используемый файловой системой для распределения пространства. В любой момент времени том состоит из информации файловой системы, набора файлов и нераспределённого пространства, оставшегося в томе, которое может быть выделено файлам. Том может занимать как весь диск, так и его часть или охватывать несколько дисков. При использовании RAID 5 том состоит из полос, охватывающих несколько дисков. Максимальный размер тома NTFS составляет 264 байт.
Кластер является фундаментальной единицей размещения в файловой системе NTFS, которая не распознаёт секторы. Кластеры, выделяемые файлу, не обязательно должны образовывать непрерывный блок; в NTFS допускается фрагментация файла на диске. Использование кластеров при размещении файлов делает систему NTFS независимой от размеров физических секторов. Это позволяет системе NTFS без препятствий поддерживать нестандартные диски с размером сектора, не равным 512 байт, а так же эффективно поддерживать диски очень большой ёмкости и файлы больших размеров посредством большего размера кластера. Эффективность обеспечивается тем, что файловая система должна отслеживать каждый кластер, выделенный файлу; использование кластеров большего размера облегчает эту задачу. Размер кластера, используемого в конкретном томе, зависят от размера тома и устанавливаются системой NTFS при форматировании.
Схема тома NTFS:
Загрузочныйсекторраздела | Главная файловая таблица | Системныефайлы | Область файлов |
Том NTFS состоит из четырёх областей. Первые несколько секторов любого тома занимает загрузочный сектор раздела (несмотря на название, размер этой области может быть до 16 секторов), содержащий информацию о схеме тома и структурах файловой системы, а так же начальная загрузочная информация и код загрузки. За этой областью следует главная файловая таблица (master file table - MFT), содержащая информацию обо всех файлах и папках этого тома NTFS, а также информацию о свободном пространстве. По сути, MTF представляет собой список всего содержимого тома NTFS, организованный в виде множества строк в структуре реляционной базы данных. За областью MTF следует область, обычно длиной 1 Мбайт, содержащая системные файлы. Среди файлов этой области находятся следующие:
- MTF2. Зеркальное отображение первых трёх строк MTF, используемых для гарантированного доступа к MTF в случае сбоя одного сектора.
- Системный журнал. Список шагов транзакций, используемый при восстановлении данных в NTFS.
- Битовая карта кластеров. Представление тома, указывающее используемые кластеры.
- Таблица определения атрибутов. Определяет типы атрибутов, поддерживаемых в этом томе, и показывает, могут ли они быть проиндексированы, а также могут ли они быть восстановлены во время системной операции восстановления.
Главная файловая таблица.
MTF организована в виде таблицы строк переменной длины, именуемых записями. Каждая строка описывает файл или папку этого тома, включая MTF, которая рассматривается как файл. Если содержимое файла достаточно мало, то оно полностью размещается в строке MTF. В противном случае строка для этого файла будет содержать частичную информацию, а оставшаяся часть файла будет распределена среди доступных кластеров тома с указателями на эти кластеры в строке MTF для данного файла.
Каждая запись MTF состоит из набора атрибутов, служащих для определения характеристик файла (или папки), а так же для определения содержимого файла.
Типы атрибутов файлов и каталогов в Windows NTFS:
Тип атрибута | Описание |
Стандартная информация | Включает атрибуты доступа (только для чтения, чтение/запись и т.д.); временные метки, включая время создания и последней модификации файла; количество каталогов, указывающих на файл (счётчик связей). |
Список атрибутов | Список атрибутов, составляющих файл, и ссылка на другую запись MTF, в которой размещены атрибуты. Используется, когда все атрибуты не помещаются в одну запись MTF. |
Имя файла | Файл (или каталог) должен иметь одно или несколько имён. |
Дескриптор безопасности | Определяет владельца файла и пользователей, которым разрешён доступ к файлу. |
Данные | Содержимое файла. Файл содержит один неименованный атрибут данных по умолчанию, и может иметь один или несколько именованных атрибутов данных. |
Корневой индекс | Используется для реализации папок. |
Размещение индекса | Используется для реализации папок. |
Информация о томе | Включает информацию, относящуюся к тому, например версия и имя тома. |
Битовая карта | Карта, предоставляющая записи, используемые MTF или каталогом. |