
 Авторефераты по всем темам >>
Авторефераты по техническим наукам
Авторефераты по всем темам >>
Авторефераты по техническим наукам
Графо-аналитический подход к анализу и контролю потоков проектных работ в автоматизированном проектировании сложных компьютеризированных систем
Автореферат докторской диссертации по техническим наукам
|
Страницы: | 1 | 2 | 3 | |
 СКАЧАТЬ ОРИГИНАЛ ДОКУМЕНТА
СКАЧАТЬ ОРИГИНАЛ ДОКУМЕНТАТеорема 2.1. Класс ПССР транслируем в класс ПГС (и обратно).
Доказательство строится на основе конструктивного подхода путем построения соответствующих корректных алгоритмов трансляции с использованием взвешенных формул вида
![]()
![]()
где ![]() аЦ составной оператор задач, помеченный символом sq, zm+1=(Mi|Ri|Li|). Каждому формируемому в процессе трансляции составному оператору ставится в соответствие вес w= 1; для
аЦ составной оператор задач, помеченный символом sq, zm+1=(Mi|Ri|Li|). Каждому формируемому в процессе трансляции составному оператору ставится в соответствие вес w= 1; для ![]() аw = n1 + 1, где n1 - количество операторов
аw = n1 + 1, где n1 - количество операторов ![]() , образующих конъюнкцию обобщенного условного оператора; для
, образующих конъюнкцию обобщенного условного оператора; для ![]() w = n2, где n2 - количество ветвей распараллеливания; для
w = n2, где n2 - количество ветвей распараллеливания; для ![]() аw = 1.
аw = 1.
Процесс трансляции считается завершенным в том и только в том случае, если сумма весов всех формул перехода равна 0:
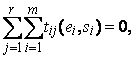
где ![]() Ц i-й терм j-й отмеченной формулы перехода, m - число термов j-й формулы, r - ранг системы отмеченных формул.
Ц i-й терм j-й отмеченной формулы перехода, m - число термов j-й формулы, r - ранг системы отмеченных формул.
Для моделирования ПССР разрабатывается структура и алгоритм функционирования абстрактной ассоциативной машины. ПССР в этом случае рассматривается как геометрическая интерпретация бинарного отношения ![]() , заданного на множестве пар элементов множества S.
, заданного на множестве пар элементов множества S.
Отношение ![]() азаписывается в виде ассоциации
азаписывается в виде ассоциации
 ,
,
где ![]() аЦ один из трех типов условных операторов множества E. Пара
аЦ один из трех типов условных операторов множества E. Пара ![]() азадает признак ассоциации, а пара
азадает признак ассоциации, а пара  аЦ значение ассоциации. Абстрактная машина имеет бесконечную вправо ленту памяти, разделенную на четыре части, головки считывания/записи и устройство управления. В первой части ленты запоминается цепочка символов входного алфавита, образованного операторами множества E, во второй - список признаков текущих ассоциаций, в третьей - описание работы абстрактной машины, в четвертой, служебной, - имена ассоциаций, участвующих в формировании условных значений ассоциаций.
аЦ значение ассоциации. Абстрактная машина имеет бесконечную вправо ленту памяти, разделенную на четыре части, головки считывания/записи и устройство управления. В первой части ленты запоминается цепочка символов входного алфавита, образованного операторами множества E, во второй - список признаков текущих ассоциаций, в третьей - описание работы абстрактной машины, в четвертой, служебной, - имена ассоциаций, участвующих в формировании условных значений ассоциаций.
В описании работы абстрактной машины различаются безусловные и условные значения ассоциаций. Безусловному значению соответствует переход по условному обобщенному оператору ![]() аили условному оператору распараллеливания
аили условному оператору распараллеливания ![]() , а условному значению - по условному оператору соединенияа
, а условному значению - по условному оператору соединенияа ![]() .
.
Разрабатывается лингвистическое представление модели ПССР, основанное на использовании предложенного скобочного языка со скобочными терминалами трех видов: открывающих и закрывающих скобок разветвления, распараллеливания и соединения.
Исследуется возможность применения ряда известных синтаксически-ориентированных методов для анализа лингвистической модели ПССР. Показывается их недостаточная эффективность как по полноте контроля, так и по затратам времени.
Предлагается метаязык RG-грамматик, обеспечивающий контроль нерегулярной скобочной структуры языка ПССР за линейное время.
Определение 1.1. RG-грамматикой языка L(G) называется четверка множеств вида
![]()
где ![]() ааЦ вспомогательный алфавит (алфавит внутренней памяти);
ааЦ вспомогательный алфавит (алфавит внутренней памяти);
![]() аЦ терминальный алфавит (может быть использован и синтермальный алфавит);
аЦ терминальный алфавит (может быть использован и синтермальный алфавит);
![]() аЦ схема грамматики G (множество имен комплексов продукций), причем каждый комплекс
аЦ схема грамматики G (множество имен комплексов продукций), причем каждый комплекс ![]() асостоит из подмножеств продукций
асостоит из подмножеств продукций![]() ;
;
![]() аЦ аксиома RG-грамматики.
аЦ аксиома RG-грамматики.
Продукция ![]() аимеет вид
аимеет вид
![]()
где ![]() аЦ имя комплекса продукций-преемников;
аЦ имя комплекса продукций-преемников;
![]() аЦ n-арное отношение, определяющее вид операции над внутренней памятью в зависимости от
аЦ n-арное отношение, определяющее вид операции над внутренней памятью в зависимости от ![]() .
.
При ![]() аникаких действий над памятью не производится.
аникаких действий над памятью не производится.
При ![]() ав ячейки
ав ячейки ![]() алент
алент ![]() азаписываются символы
азаписываются символы ![]() ,
, ![]() аЦ номер ячейки,
аЦ номер ячейки, ![]() аЦ номер ленты.
аЦ номер ленты.
При ![]() аиз ячейки
аиз ячейки ![]() алент
алент ![]() асчитываются символы
асчитываются символы ![]() ,
, ![]() - номер ячейки,
- номер ячейки, ![]() Ц номер ленты.
Ц номер ленты.
Распознавание принадлежности некоторой цепочки языку L(G), заданному R(G)аграмматикой, сводится к проверке принадлежности первого символа цепочки какой-либо продукции комплекса r0, последующие символы должны принадлежать текущему комплексу продукций-преемников, а последний символ цепочки - продукции с rkав левой части. Применение продукции сопровождается соответствующими операциями с внутренней памятью, в начале и в конце распознавания внутренняя память должна быть пуста. Алгоритм анализа, таким образом, сводится к посимвольному беступиковому просмотру проверяемой цепочки языка.
Разрабатываются подклассы RG-грамматик: монарные, детерминированные, моноидные и упорядоченные. Определяются мощность, методика минимизации и временная характеристика RG-грамматик.
Разрабатывается структура распознающего линейноограниченногоа автомата (RG-анализатора).
Основными достоинствами RG-грамматик являются: беступиковость анализа, линейная скорость анализа, малые затраты памяти, возможность анализа широкого класса языков, описывающих параллельные процессы.
Ассоциативная модель управления ППР позволяет улучшить учет критериев, параметров и специфику процесса проектирования СКС.
В третьей главе разрабатываются методы и средства, являющиеся развитием теории контроля, анализа, перевода и компиляции графических языков потоков проектных работ.
Предлагаются следующие виды автоматных графических грамматик.
- Базовая RV-грамматика, обеспечивающая контроль и анализ графических языков ППР, которые могут содержатьа неструктурированность и элементы параллелизма.
- RV-грамматика с нейтрализацией ошибок (RVN-грамматика).
- Иерархическая RV-грамматика (RVH-грамматика).
- Транслирующие RV-грамматики (в текстовый целевой язык - RVTt-грамматика и в графический целевой язык - RVTg-грамматика).
- Нечеткая RV-грамматика (RVF-грамматика).
Класс указанных грамматик является развитием и расширением RG-грамматик.
Определение 3.1. RV - грамматикой языка L(G) называется упорядоченная пятерка непустых множеств ![]() ,
,
где ![]() аЦ вспомогательный алфавит (алфавит операций над внутренней памятью);
аЦ вспомогательный алфавит (алфавит операций над внутренней памятью);
![]() аЦ терминальный алфавит графического языка, являющийся объединением множеств его графических объектов и связей (множество примитивов графического языка);
аЦ терминальный алфавит графического языка, являющийся объединением множеств его графических объектов и связей (множество примитивов графического языка);
![]() аЦ квазитерминальный алфавит, являющийся расширением терминального алфавита.
аЦ квазитерминальный алфавит, являющийся расширением терминального алфавита.
Алфавит ![]() авключает:
авключает:
- квазитермы графических объектов;
- квазитермы графических объектов, имеющих более одного входа;
- квазитермы связей-меток с определенными для них семантическими различиями, использующиеся для возврата к непроанализированным частям графического образа;
- квазитерм
 , определяющий отсутствие связей-меток и использующийся для прекращения анализа диаграммы при условии выполнения операции (ий) над внутренней памятью;
, определяющий отсутствие связей-меток и использующийся для прекращения анализа диаграммы при условии выполнения операции (ий) над внутренней памятью;
![]() аЦ схема грамматики G (множество имен комплексов продукций, причем каждый комплекс
аЦ схема грамматики G (множество имен комплексов продукций, причем каждый комплекс ![]() асостоит из подмножества
асостоит из подмножества ![]() апродукций
апродукций ![]() );
);
![]() аЦ аксиома RV-грамматики (имя начального комплекса продукций),
аЦ аксиома RV-грамматики (имя начального комплекса продукций), ![]() аЦ заключительный комплекс продукций.
аЦ заключительный комплекс продукций.
Продукция ![]() аимеет вид
аимеет вид ![]() ,
,
где а![]() аЦ n-арное отношение, определяющее вид операции над внутренней памятью в зависимости от
аЦ n-арное отношение, определяющее вид операции над внутренней памятью в зависимости от ![]() ;
;
![]() аЦ оператор модификации, определенным образом изменяющий вид операции над памятью, причем
аЦ оператор модификации, определенным образом изменяющий вид операции над памятью, причем ![]() ;
;
![]() аЦ имя комплекса продукции - преемника.
аЦ имя комплекса продукции - преемника.
В качестве внутренней памяти предлагается использовать стеки для обработки графических объектов, имеющих более одного выхода (чтобы хранить информации о связях-метках), и эластичные ленты для обработки графических объектов, имеющих более одного входа (чтобы отмечать количество возвратов к данной вершине, а, следовательно, количество входящих дуг).
Определим следующую интерпретацию правил RV-грамматики в зависимости от параметров ![]() аи
аи ![]() .
.
Пусть ![]() , тогда
, тогда ![]() , ат. е.
, ат. е. ![]() аЦ пустой оператор.
аЦ пустой оператор.
Отношение ![]() аопределяет операции над памятью, реализованной моделью стек.
аопределяет операции над памятью, реализованной моделью стек.
При ![]() аникаких действий над памятью не производится.
аникаких действий над памятью не производится.
При ![]() а
а![]() ав стек с номером
ав стек с номером ![]() азаписывается (стирается)
азаписывается (стирается) ![]() , причем если запись производится безусловно, то стирание осуществляется при условии, что
, причем если запись производится безусловно, то стирание осуществляется при условии, что ![]() ав правиле RV-грамматики и вершине стека совпадают. В противном случае данное правило считается неприемлемым (стирание не производится).
ав правиле RV-грамматики и вершине стека совпадают. В противном случае данное правило считается неприемлемым (стирание не производится).
При ![]() аоператор
аоператор ![]() аимеет вид
аимеет вид
![]() ,
,
определен для ![]() аи задает операцию записи, чтения или сравнения над ленточной памятью, где
аи задает операцию записи, чтения или сравнения над ленточной памятью, где ![]() ауказывают номера ячеек соответствующих эластичных лент
ауказывают номера ячеек соответствующих эластичных лент ![]() , куда будут записаны при
, куда будут записаны при ![]() а(считаны при
а(считаны при ![]() , сравнены при
, сравнены при ![]() ) символы
) символы ![]() .
.
При ![]() аоператор
аоператор ![]() аимеет вид
аимеет вид
![]() ,
,
определен для ![]() ,
, ![]() аи задает условную операцию над ленточной памятью, т. е. операция в числителе выполняется при условии выполнения операции в знаменателе.
аи задает условную операцию над ленточной памятью, т. е. операция в числителе выполняется при условии выполнения операции в знаменателе.
Цепочка ![]() аназывается RV-выводом
аназывается RV-выводом ![]() из
из ![]() аи обозначается
аи обозначается ![]() , если для любого
, если для любого ![]() асуществует
асуществует ![]() аи
аи ![]() атакие, что
атакие, что ![]() ,
, ![]() .
.
RV-вывод называется законченным (обозначается ![]() ), если
), если ![]() апорождается продукцией с
апорождается продукцией с ![]() ав правой части.
ав правой части.
RV- грамматика эффективна как для порождения, так и для распознавания.
Порождение некоторой цепочки языка ![]() апо его RV-грамматике
апо его RV-грамматике ![]() аначинается с применения любой из продукций комплекса
аначинается с применения любой из продукций комплекса ![]() . Эта продукция определяет начальный символ порождаемой цепочки, а кроме того, она определяет необходимую операцию над внутренней памятью и имя применимого комплекса продукций - преемников, из которых выбирается очередная продукция. Порождение заканчивается применением продукции с
. Эта продукция определяет начальный символ порождаемой цепочки, а кроме того, она определяет необходимую операцию над внутренней памятью и имя применимого комплекса продукций - преемников, из которых выбирается очередная продукция. Порождение заканчивается применением продукции с ![]() ав правой части.
ав правой части.
Распознавание принадлежности некоторой цепочки языка ![]() , заданному RV-грамматикой, аналогично RG-грамматике.
, заданному RV-грамматикой, аналогично RG-грамматике.
Методика построения RV-грамматики состоит из следующих этапов.
- Определяется терминальный алфавит контролируемого графического языка, описывается расположение меток, выявляются семантические различия для связей, имеющих общее графическое представление, строится алфавит квазитермов.
- Строится матрица допустимых паросочетаний для квазитерминального алфавита.
- Определяются отношения над внутренней памятью, обеспечивающие эффективный контроль связности графических объектов.
- По матрице допустимых паросочетаний строится граф метаязыка RV-грамматик, вершинам которого поставлены в соответствие имена комплексов правил, а дугам - квазитермы и операции над внутренней памятью.
- Производится минимизация RV-грамматики, устраняются недетерми-нированности и неопределенности.
С целью эффективной организации обработки ошибок предлагается RV-грамматика с нейтрализацией ошибок (RVN-грамматика), обеспечивающая определение всех ошибок за один проход за линейное время анализа.
Комплексы продукций RVN-грамматики дополнены комплексами-продолжателями, управление которым передается в случае обнаружения ошибки. В продукциях таких комплексов содержатся квазитермы графических объектов - продолжателей. Множество объектов - продолжателей формируется на этапе синтеза грамматики.
Внутренняя память RVN-грамматики дополнена стеком для хранения комплексов - продолжателей и лентой для хранения меток о проанализированных графических объектах.
Для иерархического описания и эволюционного доопределения вариантов сети проектов потоков работ предлагается иерархическая RV-грамматика (RVH-грамматика). В продукциях RVH-грамматики разрешается использовать не только терминальные (квазитерминальные) символы, но и нетерминалы, в качестве которых могут выступать имена комплексов продукций других грамматик (подграмматик). Для организации разбора по RVH-грамматике используется стековый механизм.
Использование RVH-грамматик позволяет сократить объем грамматики, легко модифицировать ее, эффективно конструировать грамматику из уже имеющихся подграмматик.
Предлагается нечеткая RV-грамматика (RVF-грамматика), в которой комплекс ![]() апредставляет собой нечеткое множество правил
апредставляет собой нечеткое множество правил ![]() аи степеней их принадлежности
аи степеней их принадлежности ![]() :
: ![]() , где
, где ![]() .
.
Степень принадлежности цепочки ![]() аопределяется следующим образом. Пусть цепочка
аопределяется следующим образом. Пусть цепочка ![]() является RG-выводом
является RG-выводом ![]() из
из ![]() . В каждой подцепочке вывода
. В каждой подцепочке вывода ![]() выбирается минимальное значение степени принадлежности
выбирается минимальное значение степени принадлежности ![]() , а затем из величин
, а затем из величин ![]() авыбирается максимальная по всем выводам. Рассматривается понятие прочность, понимаемое как
авыбирается максимальная по всем выводам. Рассматривается понятие прочность, понимаемое как ![]() . Под прочностью связи понимается максимальное значение прочности среди всех цепочек вывода
. Под прочностью связи понимается максимальное значение прочности среди всех цепочек вывода ![]() . Величина
. Величина ![]() апринимается за степень принадлежности
апринимается за степень принадлежности ![]() ацепочки
ацепочки ![]() аязыкуL(G), порождаемому нечеткой RV-грамматикой.
аязыкуL(G), порождаемому нечеткой RV-грамматикой.
Выводятся сравнительные оценки по времени анализа и затратам памяти для RV-грамматик, позиционных, реляционных, многоуровневых и сохраняющих графовых грамматик. Временная сложность анализа графических языков потоков работ по RV-грамматике является линейной, зависит от числа графических примитивов диаграммы потоков работ и не превышает двойного количество объектов диаграммы. Другие грамматики имеют полиномиальную или экспоненциальную оценку временной сложности. Для RVN-грамматикиа время анализа не превышает тройного количества объектов диаграммы.
Затраты памяти при работе RV-анализатора в среднем в пять раз меньше указанных формализмов.
Приводятся RV-грамматики для наиболее применяемых в практике проектирования СКС графических языков ППР: UML, IDEF, eEPC, сетей Петри, SDL, параллельных граф-схем. Определяются типы синтаксических и семантических ошибок этих языков.
Большинство графических языков потоков работ не является семантически формальными, что увеличивает их гибкость, расширяет области применения, но затрудняет машинную обработку.
Гибкость языка может привести к возникновению семейства языков, т. е. множества языков, которые концептуально имеют общую базу, но различную интерпретацию, специфичную для предметной области их применения. Большинство существующих подходов рассматривает такие языки изолированно, хотя достаточно определить обобщающую семантику для семейства языков (возможно для некоторых элементов она будет абстрактной) и специализировать семантическую составляющую отдельных элементов языка и/или диаграммы перед ее интерпретацией.
Проведенный анализ методов формализации семантики графических языков показывает, что, в основном, они основываются на двух подходах.
Первый связан со специализацией и упрощением языка, семантическая неоднозначность исчезает. Это эффективно, когда необходимо реализовать узкоспециализированное, малобюджетное инструментальное средство для автоматизации процесса проектирования, программирования и т. п.
Второй подход предполагает определять семантику динамически путем трансляции диаграмм базового языка в целевой текстовый или графический язык, который является более формальным, чем базовый. Методы этого подхода являются более перспективными, так как дают возможность на базе одного универсального инструментального средства реализовать диаграммы различных графических языков.
Для графических языков потоков работ рассматриваются следующие типы семантик: денотационная, операционная, аксиоматическая и алгебраическая.
В качестве базовых в работе используются денотационная и операционная семантики, ориентированные на реализацию второго подхода. Предлагается два типа транслирующих грамматик, позволяющих проводить синтаксически - ориентированную трансляцию диаграмм графических языков потоков работ в текстовые и графические формальные описания.
- RVTt-грамматика - целевым является текстовое формальное описание (программы на языке программирования, текст на языке спецификаций и т. п.).
- RVTg-грамматика - целевым является графическое формальное описние (например, сеть Петри).
Определение 3.2. RVTt-грамматикой языка L(G) называется упорядоченная семерка непустых множеств ![]() .
.
Множества ![]() ааналогичны RV-грамматике. Множества U и M введены с целью реализации функции трансляции. Множество
ааналогичны RV-грамматике. Множества U и M введены с целью реализации функции трансляции. Множество ![]() Ц алфавит операций над внутренней памятью, используемый целевым языком.
Ц алфавит операций над внутренней памятью, используемый целевым языком. ![]() аЦ объединение алфавитов терминальных (TT) и нетерминальных (
аЦ объединение алфавитов терминальных (TT) и нетерминальных (![]() ) символов целевого языка.
) символов целевого языка.
Продукция ![]() аимеет вид
аимеет вид
![]() ,
,
где ![]() аЦ оператор модификации определенным образом изменяющий вид операции над памятью базового (целевого) языка, причем
аЦ оператор модификации определенным образом изменяющий вид операции над памятью базового (целевого) языка, причем ![]() ;
;
![]() аЦ отображение квазитерма в терминах целевого языка (набор символов
аЦ отображение квазитерма в терминах целевого языка (набор символов ![]() ).
).
Методика построения RVTrt-грамматики дополняется этапами:
- определение отображения квазитерма в терминах целевого языка для каждой продукции, т. к. один и тот же квазитерм в зависимости от контекста может интерпретироваться разным набором символов целевого языка;
- определение операций над внутренней памятью для элементов целевого языка.
Затем минимизируются комплексы продукций и отображений. Минимизация отображений основана на поиске и свертке эквивалентных цепочек символов терминального и нетерминального алфавитов целевого языка. В качестве возможных эквивалентных фрагментов могут использоваться цепочки, не содержащие символов, для которых необходимо применять операции над внутренней памятью.
Определенная последовательность символов целевого языка обеспечивается использованием стеков для хранения информации о связях-метках, исходящих из объектов с более чем одним выходом.
Определение 3.3. RVTg-грамматикой языка L(G) называется упорядоченная восьмерка непустых множеств ![]() .
.
Множества ![]() ааналогичны соответствующим множествам RVTrt-грамматики. Элементами множества M являются графические примитивы. F={generate_input(), generate_output(), select_output(), stick_connection_points()} - множество транслирующих функций по работе с элементами множества M.
ааналогичны соответствующим множествам RVTrt-грамматики. Элементами множества M являются графические примитивы. F={generate_input(), generate_output(), select_output(), stick_connection_points()} - множество транслирующих функций по работе с элементами множества M.
Функция generate_input() формирует набор входных точек соединения, кроме той, по которой был достигнут данный графический объект. Выполняется при первичном анализе графических объектов, содержащих более одного входа.
Функция generate_output() формирует набор исходящих точек соединения. Выполняется при первичном анализе графических объектов, содержащих более одного выхода, либо когда единственный выход предполагается использовать как связь-метку, т. е. необходимо изменить направление анализа.
Функцияselect_output() производит выбор исходящей точки соединения элемента в качестве продолжателя цепочки целевого языка. Выполняется для графических объектов с динамически изменяемым числом исходящих точек соединения после формирования набора точек соединения для исходящих связей, выбирается одна из таких точек. В общем случае выбор является случайным.
Функция stick_connection_points() - связывает точки соединения связи и объекта. Выполняется при вторичном анализе графических объектов, содержащих более одного входа. Производит связывание входящей связи с точкой соединения объекта, информация о которой хранится во внутренней памяти.
Наличие этих функций позволяет сформировать алгоритм построения выходной цепочки, основными операциями в котором являются выбор точки - продолжателя анализа для объектов, содержащих более одного выхода, и компоновка целостной последовательности из уже проанализированных объектов, содержащих более одного входа и связываемых с ними анализируемых объектов.
Рассматривается схема метакомпиляции RV-грамматики, состоящая из следующих этапов.
- ексический разбор описания диаграммного языка.
- Синтаксический разбор и построение дерева разбора.
- Анализ дерева разбора и построение промежуточной структуры грамматики в терминах языка спецификаций.
- Трансляция - преобразование внутреннего представления в термины RV-грамматики.
- Оптимизация и минимизация.
- Сохранение таблиц RV-грамматики в формате XML.
В четвертой главе разрабатываются методы и средства обработки лингвистических моделей потоков проектных работ, позволяющие автоматизировать процесс разбора описаний, классификацию, построение шаблонов и синтез проектных решений потоков работ.
В качестве базового описания лингвистических моделей проектных работ выбран язык BPEL как наиболее типичный представитель этого класса языков.
В ходе анализа описания модели решаются две задачи:
- разбор описания модели и приведение его к единому унифицированному виду;
- разбор унифицированного описания, профилирование (определение параметров) и сохранение модели в базе данных.
Грамматика применяемого базового языка описания потоков проектных работ представляется в виде
![]() ,
,
где VT - множество терминальных символов, VN - множество нетерминальных символов, P - конечное подмножество (VTUVN)*x (VTUVN)+ , Os - начальный символ, K - классификационный признак.
Классификационный признак объектов моделей дает возможность проектировщику указывать на объекты, которые необходимо добавить в классификатор, или указать системе объекты, которые она классифицировать затрудняется.
Лексический, синтаксический и семантический анализаторы языка описания построены на базе нейро-семантической сети.
Лексический анализатор состоит из слоя нейронов-идентификаторов, управляющего нейрона и нейрона ошибки.
Слой нейронов-идентификаторов предназначен для анализа основных конструкций (лексем) языка: ключевых слов, идентификаторов, чисел, управляющих символов, символов-разделителей.
Нейроны-идентификаторы построены по принципу сетей адаптивно-резонансной теории (АРТ) и представляют собой векторные классификаторы. Входной вектор классифицируется в зависимости от того, на какой из множества ранее сохраненных образов он похож. Свое классификационное решение сеть APT выражает в форме возбуждения одного из нейронов.
Выход нейронов-идентификаторов представляет собой вектор ?, который соответствует унифицированному виду языка. Все выходы слоя нейронов-идентификаторов поступают на вход управляющего нейрона. Управляющие нейроны содержат веса входов, которые определяют приоритетность выходов нейронов предыдущего слоя. Наиболее приоритетный вход поступает на выход управляющего нейрона.
С выхода управляющего нейрона лексического анализатора вектор поступает на слой нейронов-идентификаторов синтаксического анализатора.
Синтаксический анализатор состоит из слоя нейронов-идентификаторов, управляющего нейрона и нейрона ошибки. Слой нейронов-идентификаторов работает аналогично слою лексического анализатора.
Отличительная особенность управляющего нейрона синтаксического анализатора состоит в том, что вектор с его выхода поступает обратно на вход нейронов-идентификаторов.
Нейроны ошибки выдают сигнал, если на входную цепочку символов нет реакции управляющего нейрона.
Параллельно работе синтаксического анализатора обработку входной цепочки осуществляет сеть управления. Сеть управления построена на базе семантической сети и составляет основу контекстного анализатора описания проектного решения. Данная сеть содержит набор правил-действий обработки символа промежуточного представления. Набор правил-действий задается фиксировано, но порядок их применения может варьироваться. Правила содержат действия, необходимые для информационного заполнения унифицированного описания артефакта модели ППР базы данных.
Сеть управления аописывается следующим образом:
![]() ,
,
где ![]() аЦ входной символ,
аЦ входной символ, ![]() аЦ реакция на данный символ,
аЦ реакция на данный символ, ![]() аЦ шаг, на который необходимо перейти после реакции.
аЦ шаг, на который необходимо перейти после реакции.
В ходе работы лексического и синтаксического анализатора строится унифицированное представление описания модели, которое в дальнейшем поступает на вход нейронов профилирования.
Нейроны профилирования заполняют векторы параметров профилирования разбираемого описания.
Для классификации профилируемых объектов используются самоорганизующиеся карты Кохонена (KCN - Kohonen Clastering Networks). Сеть KCN имеет один слой нейронов. Размерность вектора каждого нейрона равна количеству параметров профилирования P.
Точность, с которой происходит классификация представленного описания в соответствии с multidimensional scaling (MDS), имеет вид
 ,
,
где d(i,j) - расстояниеа между вычисленными параметрами модели и параметрами, хранящимися в нейроне-классификаторе и e(i,j) - евклидово расстояние между соответствующими параметрами.
Высчитывая Е, определяются модели, хранящиеся в базе данных, наиболее подходящие по типу описания к разработанной проектировщиком.
На рис. 1 представлена комплексная нейро-семантическая сеть анализа и классификации лингвистических моделей ППР.

Рис. 1. Нейро-семантическая сеть обработки модели ППР
I, IV - слои нейронов-идентификаторов, II,V -управляющие нейроны, III,VI - нейроны ошибки, VII - слой нейронов профилирования, ПП - промежуточное представление, f1, f2,Е, fn - функция преобразования, ? - унифицированный вид, НС-БД - нейро-семантическая база данных
Пятая глава посвящена разработке методов и средств реализации интеллектуальной адаптивной системы обучения проектированию нормативных и ситуационных ППР.
Выделяется несколько основных парадигм организации и реализации систем данного класса.
- Основанная на концепции специализированных экспертных систем.
- Основанная на гипертексте и гипермедиа.
- Основанная на интеграции экспертных систем и гипертеста / гипермедиа.
- Использующая концепцию интеллектуальных обучающих инструментов, представляющих собой системы со смешанной инициативой и оверлейным типом модели обучаемого.
- На основе интеграции экспертных систем с системами обучения.
Однако эти подходы слабо учитывают оценку знаний обучаемых, носящих нечеткий характер, не обеспечивают эффективную адаптацию обучаемого к учебно-практическому наполнению в ходе процесса обучения в условиях существенно различной степени первичной подготовки обучаемых, ориентированы на узкую предметную область, что снижает степень их универсальности. Таким образом, для устранения указанных недостатков необходим новый подход к организации и реализации интеллектуальных адаптивных автоматизированных обучающих систем, включающий комплекс моделей и методов, повышающий эффективность и качество обучения и позволяющий сократить сроки обучения.
Образовательное пространство проектирования нормативных и ситуационных потоков проектных работ включает следующие компоненты: проектировщик - предметная область - средства обучения - среда проектирования.
Модель предметной области автоматизированного проектирования представляется в виде дерева онтологий, которая динамически использует иерархические, порядковые и ассоциативные связи онтологий объектов и процессов проектирования. Каждой онтологии соответствует учебный элемент. Модель предметной области позволяет адекватно представить учебный материал и является базой знаний среды проектирования.
Модель предметной области имеет вид
CADModel={Архитектура, Функции, Процессы, Данные, Паттерн, MetaData| ortree, <, view},
где Архитектура={архитектураi, i=1ЕE} - множество архитектур проектирования;
Функции={функцияiн, i=1ЕZ} - множество проектных функций;
Процессы={процессi, i=1ЕP} - множество проектных процессов;
Паттерн={Операция, Команда, Способ} - множество проектных шаблонов;
Операция={операцияi, i=1ЕO} - множество проектных операций;
Команда={командаi, i=1ЕC} - множество проектных команд;
Способ={способi, i=1ЕS} - множество проектных способов выполнения команды,
Atom={понятиеi, действиеi, i=1ЕA} - множество латомов знаний, состоящее из элементарных понятий и простейших действий;
MetaData={keyi, hash-function, i=1ЕH} - метаданные модели,
где <keyi> - кортеж ассоциативных ключей, hash-function - хэш-функция поиска элемента, ortree Ц иерархическое отношение, < Ц отношение порядка, view Ц ассоциативная функция.
Структура паттернов операций, команд и способов одинакова. Например, структура PatternOperation имеет вид
PatternOperation={название, назначение, мотивация, применимость, структура, участники, отношения, результаты, реализация, пример, применения, родственные паттерны}.
Разрабатывается модель обучаемого проектировщика, отражающая динамический уровень его подготовленности к решению задач проектирования потоков работ. Уровень описан нечеткими лингвистическими критериальными параметрами (знания, умения, навык и компетентность).
Модель обучаемого проектировщика имеет вид
UserModel = { OcenkaZnaniei, OcenkaUmeniei, OcenkaNaviki, OcenkaKompetentnosti, haracteristika | calcZ, calcU, calcN, calcK, i=1ЕN},
где OcenkaZnaniei, OcenkaUmeniei, OcenkaNaviki и OcenkaKompetentnosti - массивы оценок знаний, умений, навыкова и компетентностиа соответственно, N - число контрольных точек Ki сценария. Областью значений функций расчета указанных оценок являются пары (D,![]() ): calcZ, calcU, calcN, calcK
): calcZ, calcU, calcN, calcK ![]() а(D,
а(D, ![]() ), где D - значение функции евклидово расстояние,
), где D - значение функции евклидово расстояние, ![]() аЦ значение функции принадлежности к классу проектной характеристики,
аЦ значение функции принадлежности к классу проектной характеристики,
haracteristika={оценка1, оценка2,Е, оценкаS} - множество лингвистических характеристик. calcZ: markTeori ![]() аоценкаi, calcU: marki
аоценкаi, calcU: marki ![]() оценкаi, calcN:ti
оценкаi, calcN:ti ![]() оценкаi, calcK:calcZ, calcU, calcN
оценкаi, calcK:calcZ, calcU, calcN ![]() оценкаi, где markTeori, marki, ti определены в модели протокола ниже.
оценкаi, где markTeori, marki, ti определены в модели протокола ниже.
Реализация функций calcZ, calcU, calcN, calcK выполнена с помощью предлагаемого метода диагностики на базе классификации на основе нечетких карт Кохонена (FSOM), которые хорошо зарекомендовали себя в качестве универсальных классификаторов.
|
Страницы: | 1 | 2 | 3 | |
Авторефераты по всем темам >>
Авторефераты по техническим наукам