
Разработка программно–алгоритмических средств для определения надёжности программного обеспечения на основании моделирования работы системы типа "клиент–сервер"
как аппроксимацию всего пространства, т.е. если 1–я группа обнаружила 10% всех ошибок, то она должна была найти примерно 10% всякого случайным образом выбранного подмножества, например, подмножества N2. Тогда (N1/N) » (N12/N2) и (N2/N) » (N12/N1). Тогда получаем:N = (N1 ·N2)/ N12.(А.24)
Например, две группы нашли 20 и 30 ошибок соответственно. Из них – 10 ошибок общие. Имеем согласно формуле (А.24) общее число ошибок N = 60 и из них не обнаружено 60 – 20 – 30 + 10 = 20 ошибок.
Линейная модель
В работе [16] предлагается описывать количество ошибок в программе как линейную функцию от сложности программы, то есть
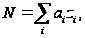
где zi – показатели сложности ПО такие как:
количество ветвлений;
количество циклов;
количество вычислений;
число комментариев;
количество вызовов функций и т.п.;
ai – весовые коэффициенты.
Методом регрессионного анализа (МНК) по данным об ошибках пяти различных проектов показано, что наибольший вклад в N вносят общее число ветвлений z4 и общее число логических операторов z6 и, что N = 0,0454 · z4 + 0,254· z6; со стандартной ошибкой – 54,4 и доверительным интервалом – 0,982.
В работе [5] рассмотрены модели количества ошибок, основанные на знании объема исходных текстов ПО. Данные модели не учитывают квалификацию программиста и подобные трудно измеримые факторы. В этих моделях используются коэффициенты пропорциональности, которые нужно искать из опытных данных не совсем ясными методами.