
Вступ до аналізу асоціативних правил
 Дата і час
– опрацювання
даних у форматі
«дата» і «час»
(наприклад,
перетворення
вхідних даних
у днях в дані
по тижнях).
Дата і час
– опрацювання
даних у форматі
«дата» і «час»
(наприклад,
перетворення
вхідних даних
у днях в дані
по тижнях).
 Квантування
значень вибірки
– процес, в
результаті
якого відбувається
розподілення
значень неперервних
даних між
скінченною
кількістю
інтервалів
заданої довжини.
Квантування
значень вибірки
– процес, в
результаті
якого відбувається
розподілення
значень неперервних
даних між
скінченною
кількістю
інтервалів
заданої довжини.
 Сортування
– сортування
записів у вхідній
вибірці даних.
Сортування
– сортування
записів у вхідній
вибірці даних.
 Злиття –
об'єднання
даних із двох
таблиць.
Злиття –
об'єднання
даних із двох
таблиць.
 Заміна –
заміна значень
згідно таблиці
підстановки.
Заміна –
заміна значень
згідно таблиці
підстановки.
 Групування
даних.
Групування
даних.
 Разгрупування
даних – відновлення
вибірки, до
якої була
застосована
операція
групування.
Разгрупування
даних – відновлення
вибірки, до
якої була
застосована
операція
групування.
Data Mining:
 Прогнозування
часового ряду.
Наприклад,
методом ковзаючого
вікна було
одержано часовий
ряд:
Прогнозування
часового ряду.
Наприклад,
методом ковзаючого
вікна було
одержано часовий
ряд:
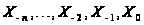 ,
а потрібно
спрогнозувати
наступне значення
,
а потрібно
спрогнозувати
наступне значення
 на основі всіх
попередніх
значень.
на основі всіх
попередніх
значень.
 Автокореляція
– автокореляційний
аналіз даних,
метою якого
є з'ясування
ступеня статистичної
залежності
між різними
значеннями
випадкової
послідовності.
У процесі
автокореляційного
аналізу розраховуються
коефіцієнти
кореляції
(міра взаємної
залежності)
для двох значень
вибірки, що
перебувають
один від одного
на певній відстані
(кількість
проміжних
значень між
ними), яку називають
також лагом.
Сукупність
коефіцієнтів
кореляції по
всіх лагах
називається
автокореляційною
функцією ряду.
За поведінкою
цієї функції
можна судити
про характер
аналізованої
послідовності:
ступеня її
гладкості,
наявності
періодичності,
тощо.
Автокореляція
– автокореляційний
аналіз даних,
метою якого
є з'ясування
ступеня статистичної
залежності
між різними
значеннями
випадкової
послідовності.
У процесі
автокореляційного
аналізу розраховуються
коефіцієнти
кореляції
(міра взаємної
залежності)
для двох значень
вибірки, що
перебувають
один від одного
на певній відстані
(кількість
проміжних
значень між
ними), яку називають
також лагом.
Сукупність
коефіцієнтів
кореляції по
всіх лагах
називається
автокореляційною
функцією ряду.
За поведінкою
цієї функції
можна судити
про характер
аналізованої
послідовності:
ступеня її
гладкості,
наявності
періодичності,
тощо.
 Лінійна
регресія –
будується
модель даних
у вигляді набору
коефіцієнтів
лінійного
перетворення.
Лінійна
регресія –
будується
модель даних
у вигляді набору
коефіцієнтів
лінійного
перетворення.
 Логістична
регресія –
будується
бінарна логістична
регресійна
модель.
Логістична
регресія –
будується
бінарна логістична
регресійна
модель.
 Нейромережа
– опрацювання
даних за допомогою
багатошарової
нейронної
мережі.
Нейромережа
– опрацювання
даних за допомогою
багатошарової
нейронної
мережі.
 Дерево рішень
– опрацювання
даних за допомогою
дерев рішень.
Дерево рішень
– опрацювання
даних за допомогою
дерев рішень.
 Самоорганізовані
карти – виконується
кластеризація
даних.
Самоорганізовані
карти – виконується
кластеризація
даних.
 Асоціативні
правила – виявлення
залежностей
між взаємозв'язаними
подіями.
Асоціативні
правила – виявлення
залежностей
між взаємозв'язаними
подіями.
 Користувацька
модель – задання
моделі вручну
за формулами.
Користувацька
модель – задання
моделі вручну
за формулами.
Інше:
 Скрипт –
застосування
моделі до нових
даних. Скрипти
призначені
для автоматизації
процесу додавання
в сценарій
однотипних
гілок обробки.
По суті скрипт
є динамічною
копією вибраної
ділянки сценарію.
При зміні
оригінальної
гілки змінюється
і скрипт, який
посилається
на неї. Наприклад,
після імпорту
даних з двох
різних баз
даних потрібно
провести їх
попередню
обробку (очистити
дані, згладити,
поміняти назви
стовпців, додати
кілька однакових
значень, тощо)
та побудувати
однакові моделі
прогнозу, а
потім експортувати
отримані дані
назад. Для першої
гілки (першої
БД) ці дії проводяться
як звичайно:
послідовними
кроками будується
ланцюжок
обробників.
Для другого
джерела (другої
БД) достатньо
буде створити
вузол імпорту,
до якого потрібно
приєднати
скрипт, що
базується на
побудованій
першій гілці.
У цьому скрипті
будуть виконані
точно такі ж
дії, як в оригінальній
гілці. На виході
скрипта ставиться
вузол експорту,
і друга гілка
є готовою до
використання.
Аналогом скриптів
є функції та
процедури в
мовах програмування:
гілка обробки
будується
один раз, а потім
за допомогою
скриптів
виконуються
закладені в
ній універсальні
обробники.
Скрипт –
застосування
моделі до нових
даних. Скрипти
призначені
для автоматизації
процесу додавання
в сценарій
однотипних
гілок обробки.
По суті скрипт
є динамічною
копією вибраної
ділянки сценарію.
При зміні
оригінальної
гілки змінюється
і скрипт, який
посилається
на неї. Наприклад,
після імпорту
даних з двох
різних баз
даних потрібно
провести їх
попередню
обробку (очистити
дані, згладити,
поміняти назви
стовпців, додати
кілька однакових
значень, тощо)
та побудувати
однакові моделі
прогнозу, а
потім експортувати
отримані дані
назад. Для першої
гілки (першої
БД) ці дії проводяться
як звичайно:
послідовними
кроками будується
ланцюжок
обробників.
Для другого
джерела (другої
БД) достатньо
буде створити
вузол імпорту,
до якого потрібно
приєднати
скрипт, що
базується на
побудованій
першій гілці.
У цьому скрипті
будуть виконані
точно такі ж
дії, як в оригінальній
гілці. На виході
скрипта ставиться
вузол експорту,
і друга гілка
є готовою до
використання.
Аналогом скриптів
є функції та
процедури в
мовах програмування:
гілка обробки
будується
один раз, а потім
за допомогою
скриптів
виконуються
закладені в
ній універсальні
обробники.
 Калькулятор
– дозволяє
сформувати
нове поле вибірки
як результат
обчислень над
даними з інших
полів.
Калькулятор
– дозволяє
сформувати
нове поле вибірки
як результат
обчислень над
даними з інших
полів.
 Умова
– дозволяє
організувати
умовне виконання
сценарію обробки
даних.
Умова
– дозволяє
організувати
умовне виконання
сценарію обробки
даних.
 Команда OC –
забезпечує
формування
й запуск різних
команд операційної
системи.
Команда OC –
забезпечує
формування
й запуск різних
команд операційної
системи.
Залежно від обраного методу Майстер обробки буде містити різне число кроків і набір параметрів, що надбудовуються на кожному кроці. На кожному кроці Майстра обробки доступні кнопки «Далі», «Назад» та «Скасувати».
Майстер візуалізації даних
Майстер візуалізації допоможе в інтерактивному покроковому режимі вибрати та налаштувати найбільш зручний спосіб подання даних. В залежності від обраного способу візуалізації будуть налаштовуватись різні параметри, а Майстер, відповідно, буде містити різне число кроків.
Для виклику
Майстра візуалізації
можна скористатися
кнопкою
 «Майстер
візуалізації»
на панелі
інструментів
«Майстер
візуалізації»
на панелі
інструментів
 «Сценарії»,
попередньо
виділивши
потрібну гілку
у сценарії
опрацювання
або вибравши
відповідну
команду з
контекстного
меню для даної
гілки сценарію.
«Сценарії»,
попередньо
виділивши
потрібну гілку
у сценарії
опрацювання
або вибравши
відповідну
команду з
контекстного
меню для даної
гілки сценарію.
Виконання аналізу асоціативних правил
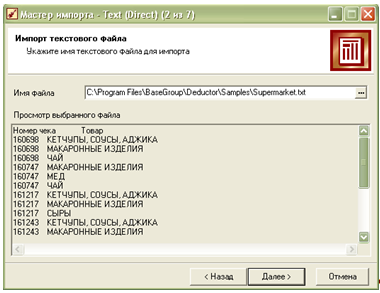
На першому
кроці необхідно
імпортувати
дані в Deductor.
Використовуючи
кнопку
 ,
вказуємо шлях
до текстового
файлу з роздільниками.
Для прикладу,
можна вибрати
один із готових
прикладів у
папці «Samples»
– Supermarket.txt:
,
вказуємо шлях
до текстового
файлу з роздільниками.
Для прикладу,
можна вибрати
один із готових
прикладів у
папці «Samples»
– Supermarket.txt:
Пілся натискування кнопки «Далі» вказуємо тип роздільника та інші параметри імпорту. Наступним кроком є вказання параметрів стопвпців:
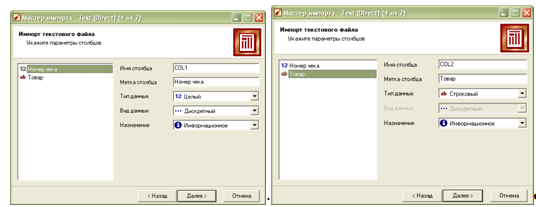
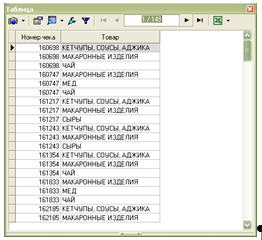
Після цього натискаємо кнопку «Далі», а потім – «Пуск». Після виконання процесу імпорту даних з текстового файлу потрібно вибрати спосіб їх відображення (за замовчуванням – таблиця). Після цього маємо дані, готові для опрацювання:
асоціативний правило аналітичний
Стаємо на
відповідну
гілку в сценарії
та натискаємо
кнопку
 Майстра обробки
даних:
Майстра обробки
даних:
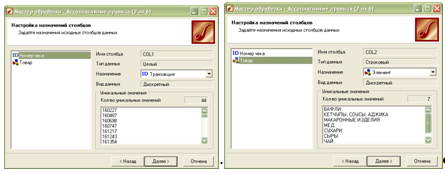
Серед
методів опрацювання
даних вибираємо
Асоціативні
правила, після
чого потрібно
вказати, який
стовпець відповідає
за номер чи
ідентифікатор
транзакції,
а який містить
самі елементи
(в даному випадку
– покупки):
Наступне вікно дозволяє вказати значення мінімальних та максимальних підтримки та достовірності правил:
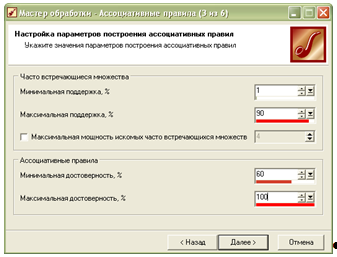
В наступному вікні натискаємо кнопку «Пуск», після чого здійснюється аналіз згідно вказаних значень:
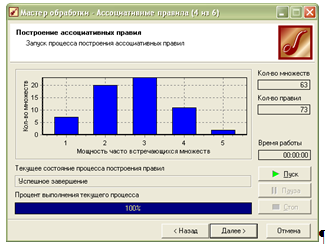
Далі знову пропонуються різні способи візуалізації даних. Вибираємо всі способи відображення, що знаходяться в групі «Data Mining». В результаті одержуємо:
Набір асоціативних правил з вказанням їх підтримки, достовірності та кількості.
Популярні набори елементів (в даному випадку – покупок).
Дерево правил за наслідком, наприклад:
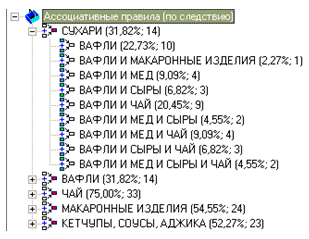
що буде показувати, після покупки яких продуктів далі ймовірно будуть куплені сухарі.
Можливість розрахувати умову «якщо... то...»: наприклад, можна вказати умову «вафлі», а потім натиснути кнопку «Розрахувати правила» або Ctrl+Enter. Після цього внизу в області наслідку з’являться відповідні записи «чай», «сухарі», «сухарі і чай» з вказанням всіх параметрів.
Размещено на
1 Приклад з підручника: Методы и модели анализа данных: OLAP и Data Mining / А. А. Барсегян, М. С. Куприянов, В. В. Сепаненко, И. И. Холод.
2 Імплікація — логічний оператор «якщо …, то …».
3 ADO (від англ. ActiveX Data Objects — «об'єкти даних ActiveХ») — інтерфейспрограмування ужитків для доступу до даних, розроблений компанією Microsoft (MS Access, MS SQL Server), що базується на технології компонентів ActiveX. ADO дозволяє представляти дані з різноманітних джерел (реляційних баз даних, текстових файлів і т.д.) в объектно-орієнтованому вигляді.