
Читайте данную работу прямо на сайте или скачайте

Управление потоками данных в параллельных алгоритмах вычислительной линейной алгебры
Необходимость решения сложных фундаментльных и прикладных задач постоянно обуславливает исследования в области разработки и создания высокопроизводительных вычислительных средств. Производительности современных ЭВМ недостаточно для обеспечения требуемого решения многих задач. Один из наиболее эффективных способов повышения производительности заключается в распараллеливании вычислений в многопроцессорных и параллельных структурах.
В параллельном программировании, так же как и в последовательном, существует много различных средств для создания параллельного программного обеспечения. В данном разделе мы кратко опишем лишь несколько средств непосредственного программирования (кодирования) параллельных алгоритмов.
Все инструменты для разработки параллельных программ можно разделить на несколько типов:
1. Concurrent C++ (CC++) и Fortran M (FM). Эти языки предоставляют собой небольшой набор расширений языков C++ и Fortran и предоставляют программисту явное правление параллелизмом, коммуникациями и распределением заданий между процессорами. Языки CC++ и FM лучше всего подходят для реализации алгоритмов, в которых присутствуют динамическое создание заданий, нерегулярные схемы коммуникаций, а также для написания библиотек параллельного программирования. Недостатком программ, созданных с помощью данных языков программирования, является их недостаточная переносимость. Кроме того, компиляторы этих языков не всегда входят в стандартный комплект программного обеспечения, поставляемый с компьютером.
2. межпроцессных коммуникаций (interprocess communication) такие как разделяемая память (shared memory), семафоры (semaphores), очереди сообщений (message queues), сигналы (signals) удобно использовать при программировании в модели разделяемой памяти. При использовнии низкоуровневых средств межроцессных коммуникаций программисту кроме кодирования непосредственно вычислительного алгоритма, требуется самому создавать процедуры синхронизации процессов, что может быть источником дополнительных трудностей.
3. Parsytec, поставляеются со специализированной операционной системой Parix, обеспечивающей реализацию параллельных алгоритмов на программном ровне. ОС Parix предоставляет разработчику библиотеку системных функций, обеспечивающих синхронную и асинхронную передачу данных, получение информации о конфигурации вычислительного зла, на котором запущена программа и т.д. Недостатком таких библиотек является их специализированность, т.е. зкая направленность на конкретную параллельную машину и, как следствие, плохую переносимость.
4. MPI называют ассемблером для параллельных систем).
В рамках данной дипломной работы была создана система FLOWer Ч набор тилит, облегчающих написание параллельных программ. В основе системы лежит модель правления потоком данных. Обычно в вычислительных системах, управляемых потоком данных, команды машинного ровня правляются доступностью данных, проходящих по дугам графа потока данных (ГПД). В данной системе используется принцип правления крупненным потоком данных (Large-Grain Data Flow), в котором единица планирования вычислений - процесс - крупнее (возможно, намного крупнее), чем одна машинная команда.
Для задания ГПД был разработан специальный язык DGL (Dataflow Graph Language). ГПД, записанный на этом языке, легко настраивается под конкретную многопроцессорную систему - число вершин и дуг графа может определяться через внешние параметры, которые вводятся пользователем, считываются из файла или задавются каким-либо другим способом. В качестве параметров можно использовать число процессоров в системе, степень загруженности системы и т.д.
В состав системы FLOWer входят:
DGL;
Структура параллельной программы, написанной в системе FLOWer, мало отличается от структуры последовательной программы. Так, процессы записываются ввиде отдельных функций, которые считавают значения параметров из входных дуг ГПД и передают результат в выходные. Использование модели правления потоком данных позволяет избежать сложностей, связанных с синхронизацией. Правда часто это достигается за счет некоторого снижения эффективности программы.
Цель данной работы - реализовать ряд алгоритмов вычислительной линейной алгебры в данной модели вычислений, оценить теоретически их эффективность и сравнить полученные результаты с экспериментальными данными.
Основные понятия параллелелизма
Определение.Степенью параллелизма численного алгоритма называется число его операций, которые можно выполнять параллельно.
Определение.Средней степенью параллелизма численного алгоритма называется отношение общего числа операций алгоритма к числу его этапов.
Определение.Ускорением параллельного алгоритма называется отношение

где T1 - время выполнения алгоритма на одном процессоре, Тp - время выполнения алгоритма в системе из p процессоров.
Параллельный алгоритм называется масштабируемым, если при величении числа процессоров производительность также величивается. В идеальном случае
Определение.Ускорением параллельного алгоритма по сравнению с наилучшим последовательным алгоритмом называется отношение
где TТ1 - время выполнения алгоритма на одном процессоре, Тp - время выполнения алгоритма в системе из p процессоров.
Определение.Эффективностью параллельного алгоритма называется величина

Очевидно, что Sp SYMBOL 163 f "Symbol" s 12га p, SТp SYMBOL 163 f "Symbol" s 12га Sp, Ep SYMBOL 163 f "Symbol" s 12г. Если алгоритм достигает максимального скорения (Sp = p), то Ep = 1.
Одной из целей при конструировании параллельных алгоритмов является достижение по возможности большего скорения. Но максимальное ускорение можно получить только для тривиальных задач. Главные факторы, влияющие на снижение скорения таковы:
Определение.Временем подготовки данных называется задержка, вызванная обменами, конфликтами памяти или синхронизацией и необходимая для того, чтобы разместить данные в соответствующих ячейках памяти.
Большинство алгоритмов представляют собой смесь фрагментов с тремя различными степенями параллелизма, которые мы будем называть максимальным, частичным и минимальным параллелизмом. Но даже если алгоритм обладает максимальным параллелизмом, ситуация для данной параллельной системы может осложнятся проблемой балансировки нагрузки. Под балансировкой нагрузки понимается такое распределение заданий между процессорами системы, которое позволяет занять каждый процессор полезной работой по возможности большую часть времени. Балансировка нагрузки может осуществляться как статически, так и динамически.
Рассмотрим формальную модель системы, в которой
где SYMBOL 97 f "Symbol" s 12a1 - доля операций, выполняемых только одним процессором, SYMBOL 97 f "Symbol" s 12a2 - доля операций, выполняемых со средней степенью параллелизма k < p, SYMBOL 97 f "Symbol" s 12a3 - доля операций, производимых со степенью параллелизма p, td - общее время, требуемое для подготовки данных.
Различают несколько специальных случаев этой формулы.
Случай 1.SYMBOL 97 f "Symbol" s 12a1 = 0, SYMBOL 97 f "Symbol" s 12a2 = 0, SYMBOL 97 f "Symbol" s 12a3 = 1, td = 0. Здесь скорение максимально.
Случай 2.SYMBOL 97 f "Symbol" s 12a1 = 0, SYMBOL 97 f "Symbol" s 12a2 = 1, SYMBOL 97 f "Symbol" s 12a3 = 0, td = 0. Теперь Sp = k < p.
Случай 3.SYMBOL 97 f "Symbol" s 12a1 = SYMBOL 97 f "Symbol" s 12aSYMBOL 97 f "Symbol" s 12a2 = 0, SYMBOL 97 f "Symbol" s 12a3 = 1 - SYMBOL 97 f "Symbol" s 12atd = 0. В этом случае

Данная формула выражает закон Амдаля-Уэра. Следует отметить очень быстрое убывание Sp для малых значений SYMBOL 97 f "Symbol" s 12a
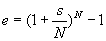
Используя последнюю формулу, можно примерно оценить долю параллельных вычислений
Случай 4. td велико. Этот случай показывает, что при достаточно большом td можно получить Sp < 1. Таким образом, возможно, что для задач с интенсивными обменами использование нескольких процессоров оказывается менее выгодным, чем использование одного.
При вычислении скорения по описанным формулам возникает ряд трудностей. В частности, задача, решаемая с большим числом процессоров может не помещаться в оперативной памяти единственного процессора; исследование ускорения должно проводится для больших задач, которые слишком велики для того, чтобы их можно было решить за разумное время с помощью единственного процессора.
Подход к измерению скорения, который потенциально может честь обе названные проблемы, состоит в том, чтобы измерять скорость вычислений по мере того, как растут размер задачи и число процессоров. Рассмотрим, например, задачу матрично-векторного множения Ax. Если A- n*n-матрица, то потребуется 2n2 - n операций. Предположим, что при исходном порядке n вычисления на единственном процессоре идут со скоростью 1 MFLOP. Затем мы дваиваем n, и число операций при большом n величивается примерно в 4 раза. Если задача решается на 4 процессорах со скоростью 4 MFLOP, то мы достигли максимального скорения.
Вообще, пусть размер задачи определяется параметров n, число операций есть f(n) при растущем n и p = SYMBOL 97 f "Symbol" s 12af(n). Если n1 - размер задачи, посильный для одного процессора, то соответствующий размер задачи np для системы из p процессоров определяется равенствома f(np) = pf(n1) (чтобы число операций, выполняемых p процессорами, в p раз превосходило число операций одного процессора).
Определение.Параллельный алгоритм обладает свойством локальности, если он использует локальные данные гораздо чаще, чем даленные. Наряду с параллелизмом и масштабируемостью это свойство является основным требованием к параллельному програмному обеспечению. Важность этого свойства определяется отношением стоимостей удаленного и локального обращения к памяти. Это отношение может варьироваться от 10:1 до 1:1 и больше, что зависит от используемой аппаратуры.
Метод оценки производительности
Задачей программиста является проектирование и реализация программ, которые удовлетворяют требованиям пользователя в смысле производительности и корректной работы. Производительность является достаточно сложным и многосторонним понятием. Кроме времени выполнения программы и масштабируемости следует также анализировать механизмы, отвечающие за генерацию, хранение и передачу данных по сети, оценивать затраты, связанные с проектированием, реализацией, эксплуатацией и сопровождением программного обеспечения. Существуют весьма разнообразные критерии, с помощью которых оценивается производительность. Среди них могут присутствовать: время выполнения программы, скорение и эффективность, требования по памяти, производительность сети, время задержки при передаче данных (latency time), переносимость, масштабируемость, затраты на проектирование, реализацию, отладку, требование к аппаратному обеспечению и т.д.
Относительная важность разнообразных критериев будет меняться в зависимости от природы поставленной задачи. Специфика конкретной задачи может требовать высоких показателей для каких-либо определенных критериев, в то время как остальные должны быть оптимизированы или полностью игнорированы. В данной работе основное внимание деляется скорению параллельного алгоритма.
Для вычисления приближенной оценки производительности алгоритма будем читывать только наиболее трудоемкие элементарные команды, такие как умножение двух чисел и пересылка данных.
Рассмотрим задачу о пересылке n чисел из памяти одного процессора Р1 в память другого процессора Р2. В общем случае такая пересылка реализуется посредством некоторой комбинации аппаратных средств и программного обеспечения и ее стандартный сценарий может выглядеть следующим образом. Прежде всего данные загружаются в буферную память или собираются в последовательных ячейках памяти процессора Р1. Затем выполняется команда переслать, результатом которой является перенос данных в буфер или память процессора Р2. Далее процессор Р2 выполняет команду принять, и данные направляются на места своего конечного назначения в памяти Р2. Чтобы освободить основные процессоры от значительной части этой работы, можно использовать сопроцессоры.
В этом прощенном описании опущены многие детали (в большей степени зависящие от конкретной системы), но главные пункты сохранены: чтобы переслат данные, их вначале нужно выбрать из памяти передающего процессора, должна быть предоставлена информация, куда следует их послать, должен произойти физический перенос данных от одного процессора к другому и, наконец, данные нужно разместить в надлежащих ячейках памяти принимающего процессора. Для многих систем время такого обмена можно выразить приближенной формулой
где Tstart Ч время запуска, Tsend Ч время, необходимое для пересылки одного числа.
Подобным образом оценивается время перемножения и сложения n пар чисел. Будем считать, что n пар чисел перемножаются за время nTmul, складываются за время nTadd. При этом не будем различать операции сложения и вычитания, и операции множения и деления. Экспериментально было становлено, что время Tmulа на порядок превосходит время Tadd (конкретное значение зависит от типа процессора и отношение Tmul/Tadd варьируется примерно от 10 до 100). Поэтому часто при оценке времени выполнения алгоритма операции сложения не читываются.
- А С Т Ь 1
СИСТЕМА FLOWer
В данной части описывается система программирования FLOWer - набор инструментов, в значительной степени облегчающих создание и отладку параллельных программ. Эта система написана на языке Delphi и предназначена для работы в локальных сетях ЭВМ под правлением ОС Windows.
Г Л А В 1
Программный комплекс FLOWer спроектирован для работы в массивно-параллельной системе (MPP), которая состоит из однородных вычислительных злов, включающих в себя:
Узлы связаны через некоторую коммуникационную среду (высокоскоростная сеть, коммутатор и т.п.). На каждом зле работает полноценная ОС (в данном случае Windows).
В частности, такой системой является локальная сеть, в которой любые два компьютера могут обмениваться данными друг с другом. На любом компьютере могут одновременно работать несколько процессов.
Данная работа была выполнена в локальной сети с общей шиной. В такой сети все процессоры соединены посредством шины. Достоинством такой системы является очень малое число линий связи, однако возможны задержки (конфликт на шине) при использовании шины несколькими процессорами. Это может стать серьезной проблемой при величении числа процессоров.
В состав системы FLOWer входят:
DGL;
Запуск параллельной программы осуществляется под правлением диспетчера, который распределяет процессы по компьютерам и устанавливает связи между процессами. Для нормальной работы диспетчера на всех компьютерах должна быть запущена специальная программа - монитор.
Создание параллельной программы в системе FLOWer состоит из следующих шагов:
DGL
DGL
DLL
DGL
Г Л А В 2
МОДЕЛЬ ВЫЧИСЛЕНИЙ
Система FLOWer базируется на модели правления потоком данных. В данной модели вычислений программа представляется в виде ГПД. Вершины ГПД соответствуют отдельным процессам - последовательным часткам программы, дуги задают отношения между ними. Точка вершины, в которую входит дуга, называется входным портом (портом импорта или входом), точка, из которой она выходит, - выходным (портом экспорта или выходом). Некоторые входные порты могут быть помечены как обязательные. По дугам передаются данные из одного процесса в другой.
Основная идея модели правления потоком данных заключается в том, что процесс планируется для исполнения тогда и только тогда, когда во все его обязательные входные порты поступят данные. Т.е. процесс может быть запущен на выполнение, если выполняется одно из следующих словий:
Введение необязательных входов выводит данную модель за рамки стандартной модели правления потоком данных, но придает системе дополнительную гибкость.
Первым запускается на выполнение процесс, помеченный как стартовый. После этого параллельная выполняется до тех пор, пока не завершится процесс, помеченный как завершающий. Программа может включать несколько стартовых и завершающих процессов, причем один и тот же процесс может быть одновременно и стартовым и завершающим.
После запуска процесс может взаимодействовать с другими процессами только через каналы. Когда процесс читает данные из входа, его работа приостанавливается до момента поступления данных (предусмотрены функции для асинхронного обмен сообщениями). Входы используются как очереди, и они, подобно каналам в ОС UNIX, буферизуют одно или несколько сообщений до тех пор, пока их не получит адресат. Объем буфера ограничен только доступной емкостью памяти. Каждый вход может быть связан с несколькими выходами.
Далее будут рассмотрены структуры данных для записи ГПД.
2.1. ГПД
ГПД (Граф Потока Данных) Ч ориентированный граф, вершинами которого являются процессы, дугами - каналы. Каждому процессу сопоставлена пара чисел, однозначно определяющая этот процесс, - номер класса процесса и номер экземпляра процесса (о необходимости введения двумерной нумерации процессов будет рассказано несколько позже).
Различие между классом и экземпляром процесса такое же, как и в объектно-ориентированных языках программирования.
Канал определяет однонаправленный поток данных между процессами, он всегда направлен от входа канала к выходу. Между каналами и выходами имеется взаимооднозначное соответствие; в то же время вход может быть соединен с несколькими выходами. Каждому каналу приписывается вес - величина, характеризующая примерный объем данных, пересылаемых по каналу.
Процесс Ч структура данных, состоящая из набора входов и выходных портов (не путать с выходами). Входы и выходные порты занумерованы. Вход может быть помечен как обязательный. Каждому процессу приписывается вес - величина, характеризующая примерный объем вычислений, выполняемых этим процессом.
Выходной порт Ч массив выходов.
Выход - тройка чисел <номер класса процесса, номер экземпляра процесса, номер входа>, однозначно определяющая вход, к которому подключен данный выход.
Введем систему обозначений.
Pi Ча процессы с номером (i, x), где x < | Pi |.
Pij Ча процесс с номером (i, j).
In Pij Ча множество входов процесса (i, j).
In Pij | Ча число входов процесса (i, j).
In k Pij Ча k-й вход процесса (i, j).
Out Pij Ча множество выходов процесса (i, j).
Out k Pij Ча выходы процесса (i, j) с номерами (k, x), где x < | Out k Pij |
Out kl Pij Ча выход с номером (k, l).
Out kl Pij, тогда выход X соединен с входом h = X.in процесса с номером (s, w), где s = X.proc, w = X.copy. Т.е. существует канал c = (X, Y), где Y = In h Psw.
2.2. Шаблона ГПД
Шаблоны ГПД имеют сходные черты с шаблонами в языке С++. Каждый шаблон ГПД обладает набором параметров, после определения которых из шаблона получается конкретный экземпляр ГПД. От параметров может зависеть число процессов ГПД, число выходов процесса. Параметры шаблона вводятся на этапе запуска программы. Это позволяет настраивать программу под конкретные требования пользователя.
Для записи шаблона ГПД был разработан специальный язык DGL (Dataflow Graph Language). Более подробно о DGL можно прочитать в главе Язык DGL.
Шаблон ГПД - это ориентированный граф, вершинами которого являются классы процессов, дугами - каналы, и набор параметров. Каждому классу процесса сопоставлен номер.
Параметры Ч вектор переменных.
Канал определяет однонаправленный поток данных между процессами, он всегда направлен от входа к выходу.
Класс процесса Ч структура данных, состоящая из набора входов и выходов. Входы и выходы занумерованы. Вход может быть помечен как обязательный.
Введем систему обозначений.
Ai - i-й параметр (целое число).
TPi - i-й процесс.
In TPi - множество входов процесса i.
In k TPi - k-й вход процесса i.
Out TPi - множество выходов процесса i.
Out k TPi - k-й выход процесса i.
Пусть X = TPi. Тогда
X.ncopies = ncopies (A) - целочисленная функция от параметров, которая задает число копий процесса X.
Пусть X = Out k TPi. Тогда
X.ncopies = ncopies (p, A) - целочисленная функция, которая задает число копий выхода X. Здесь p Ч целое число, А - параметры.
X.proc - номер процесса, с входом которого соединен данный выход.
X.copy = copy (c, p, A) - целочисленная функция. Здесь p и c - целые числа, А - параметры.
X.in - номер входа, с которым соединен данный выход.
2.3. Связь ГПД и шаблона ГПД
Пусть TG (TP, TC, TA) - шаблон ГПД, A - конкретные значения параметров. Введем операцию подстановки Subst параметров А в шаблон TG.
G = Subst A TG Ч ГПД такой, что
TPi сопоставлено множество процессов Pi.
Pi | = (TPi).ncopies (A).
In Pijа = In TPi, где j < | Pi |.
Out k TPi сопоставлено множество выходов Out k Pij, где j < | Pi |.
| Out k Pij | = (Out k TPi).ncopies (j, A), где j < | Pi |.
(Out kl Pij).proc = (Out k TPi).proc, где l < | Out k Pij |, j < | Pi |.
(Out kl Pij).copy = (Out k TPi).copy (l, j, A), где l < | Out k Pij |, j < | Pi |.
(Out kl Pij).in = (Out k TPi).in, где l < | Out k Pij |, j < | Pi |.
ЗАМЕЧАНИЕ: при некоторых значениях вектора параметров операция подстановки может быть не определена.
Г Л А В 3
ЯЗЫК DGL
Язык DGL был специально разработан для описания ГПД. Для ввода програмы на языке DGL можно использовать как простой текстовый редактор, так и специальную программу Rose, которая рисует ГПД на экране компьютера.
Рассмотрим как зписываются графы на языке DGL на основе элементарных примеров.
1. Out вершины V1 связан со входом In вершины V2.
process V1 { export: Out à V2:In; }
process V2 { import: In; }
2. Имеется N вершин V0, Е, VN-1. Вершина W содержит N выходов Out0, Е, OutN-1. Выход Outk соединен со входом In вершины Vk, k = 0, Е,(N-1).
process V[N] { import: In; }
process W { export: Out [N] à V[c]:In; }
3. Имеется N вершин V0, Е, VN-1. Выход Out вершины k соединен со входом In вершины W, k = 0, Е,(N-1).
process W { import: In; }
process V[N] { export: Out à W:In; }
4. Имеется N вершин V0, Е, VN-1 и N вершин W0, Е, WN-1. Выход Out вершины Vk связан со входом In вершины Wk, k = 0, Е, (N-1).
process V[N] { export: Out à W[p]:In; }
process W[N] { import: In; }
5. Имеется N вершин V0, Е, VN-1 и M вершин W0, Е, WM-1. Каждая вершина типа V содержит M выходов Out0, Е, OutM-1, причем выход Outk связан со входом In вершины Wk, k = 0, Е, (M-1).
process W[M] { import: In; }
process V[N] { export: Out [M] à W[c]:In; }
6. Имеется N вершин V0, Е, VN-1. Выход Out вершины Vk связан со входом In вершины V(k+1) mod N, k = 0, Е, (N-1).

process V[N] { export: Out à V[(p+1) mod N]:In;а import: In; }
Значение N может быть объявлено как внешний параметр. В этом случае N определяется во время запуска программы.
В дальнейшем планируется ввести в язык многомерные массивы процессов, так же добавить условные операторы ifЕthenЕelse и caseЕof. Это позволит описывать более сложные ГПД, в частности, многомерные решетки.
Синтаксис
DGL ::=
лDATAFLOW лPROGRAM name л;
{лEXTERN name [л= integer] л;}
{лCONST name л= expression л;}
{process}
process ::=
PROCESS name [л[number_of_instances л]]а
{directive л;}
л{
{process_attr л;}
EXPORT: {export}
лIMPORT: {import}
л}
directive ::=
LOCAL | START | TERMINATION
process_attr ::=
weight л= integer
import ::=
name [л{ import_attr {л; import_attr} л}] л;
export ::=
name [л[ number_of_instances л]]
л-->
process_name
[л[ process_index л]]
л:
import_name
[л{ export_attr {л; export_attr} л}]
л;
number_of_instances ::=
expression
process_index ::=
expression
import_attr ::=
ARGUMENT
export_attr ::=
DATASIZE л= integer
Г Л А В 4
ПРИМЕР ПАРАЛЛЕЛЬНОЙ ПРОГРАММЫ
В качестве примера рассмотрим задачу приближенного вычисления числа Пи с использованием правила прямоугольников для вычисления определенного интеграла
где 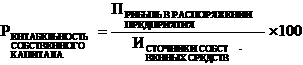
Согласно правилу прямоугольников,

где 

Следует отметить, что это процессорная программа. Она не затрагивает многие проблемы параллельного программирования, например критическое влияние процессов ввода-вывода. Тем не менее эта задача поможет ознакомиться с основными принципами построения программ, работающих в соответствии с методом правления потоком данных.
Существует множество подходов к решению контрольной задачи. Решение, приведенное ниже, иллюстрирует все основные шаги разработки программы.
4.1. Конструирование ГПД программы
В пределе разрабатываемая программа может быть создана в виде одного процесса, но при этом теряется параллелелизм. Можно создать множество мелких процессов, таких как один оператор или даже одна арифметическая операция, что приведет к резкому величению расходов, связанных с запуском каждого процесса и обменом данных между ними. Следует отметить, что структура решаемой задачи часто наводит на хорошее первое приближение.

Для подсчета числа Пи используется несколько рабочих процессов, которые вычисляют свои части интеграла и пересылают результат суммирующему процессу. Рабочие процессы обращаются за очередным заданием к процессу распределения работ. Вся работа не распределяется заранее равномерно между процессами: один рабочий процесс, если он запущен на более быстрой машине, может выполнить львиную долю работы.
4.2. Запись ГПД на языке DGL
После того, как граф данных нарисован, каждый процесс, начало и конец каждой дуги помечаются буквенно-цифровым именем, которое используется в языке DGL. Перевод графа потока данных в язык DGL совершается однозначным образом. Каждой вершине ГПД соответствует процесс DGL с тем же именем.
Теперь нарисуем ГПД с помощью программы Rose и запишем его на диск в формате DGL.

DATAFLOW PROGRAM PI;
EXTERN NProcs = 5;
CONST nw = MAX (1, NProcs - 2);
PROCESS Summer [1]; LOCAL;
{
IMPORT:
NumIter {};
PartSum {};
}
PROCESS Worker [nw];
{
EXPORT:
PartSum [1] --> Summator [0] : PartSum {DATASIZE = 0};
Demand [1] --> Manager [0] : DemandList {DATASIZE = 0};
IMPORT:
Arg {};
}
PROCESS Manager [1]; LOCAL; START; TERMINATION;
{
EXPORT:
Done [1] --> Summator [0] : DoneSignal {DATASIZE = 0};
Worker [nw] --> Worker [c] : Arg {DATASIZE = 0};
IMPORT:
DemandList {};
}
4.3. Компиляция процессов
После того, как ГПД записан на языке DGL, его нужно обработать транслятором dglc. В результате работы транслятора на диске должны появиться следующие файлы: PI.dpr, Manager.pas, ManagerBody.pas, Worker.pas, WorkerBody.pas, Summator.pas, SummatorBody.pas. Далее, программист записывает код каждого процесса в файлах SummatorBody.pas, WorkerBody.pas, ManagerBody.pas, затем компилирует проектный файл PI.dpr.
Ч А С Т Ь 2
РЕАЛИЗАЦИЯ НЕКОТОРЫХ АЛГОРИТМОВ ВЛА В
СИСТЕМЕ FLOWer
В данной части рассматривается реализация в системе программирования FLOWer некоторых алгоритмов ВЛА, в число которых входят множение матриц, LU-разложение, решение треугольных СЛУ, QR-разложение, итерационные методы решения СЛУ. Для каждого алгоритма приводятся теоретические оценки скорения, описание параллельного алгоритма, экспериментальные данные. Для проведения экспериментов использовалась локальная сеть FastEthernet, состоящая из 4-х компьютеров Pentium II MHz.
Г Л А В 1
Рассмотрим задачу вычисления произведений Ax и AB, где А и В - матрицы, х - вектор. Отдельно будут рассмотрены ленточные и блочно-диагональные матрицы.
1.1. множение матрицы на вектор
Пусть А - матрица m´n, х - вектор длины n.Тогда произведение можно записать двумя способами
 аили
аили 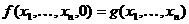
где аi - i-я строка матрицы А, аi - i-й столбец матрицы А, а (x, y) - скалярное произведение. Различие способов записи можно рассматривать как различие двух способов доступа к данным, что приводит к разным алгоритмам и для задач матричного множения и решения линейных систем.
Пусть система состоит из р процессоров. Рассмотрим сначала векторно-матричное произведение с помощью линейных комбинаций: p = n и xi
и ai приписаны процессору i.Все произведения
xiai вычисляются с максимальным параллелизмом, а затем выполняются сложения по методу сдваивания. Причем синхронизация в данной модели не требуется.
лгоритм скалярных произведений в некоторых отношениях более привлекателен. Пусть p = m, x и ai приписаны процессору i. Каждый процессор выполняет свое скалярное произведение, и при этом паралелизм максимален.
Выбор алгоритма вычислений зависит от целого ряда обстоятельств. Матрично-векторное множение неизбежно является частью более широкого процесса вычислений, и основную роль играет способ хранения матрицы А и вектора х. Еще одно существенное соображение - желаемое расположение результата по окончании множения: в первом случае результат размещается в памяти одного процессора, тогда как в другом он размещен между процессорами.
В реальных системах n и m значительно больше числа процессоров, и каждому процессору передаются несколько строк или столбцов.
1.2. Матричное множение
налогично рассматриваются алгоритмы множения матриц А и В.
Пусть матрицы разбиты на блоки
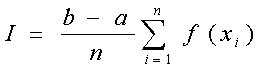
Пусть число процессоров р равно числу st блоков матрицы С. Тогда все блоки можно вычислять одновременно. Рассмотрим специальные случаи разбиения:
s = 1 - матрица А разбита на группы столбцов;
t = 1 - матрица В разбита на группы строк;
s = t = 1 Ч алгоритм блочного скалярного произведения;
r = 1 - алгоритм блочного внешнего произведения.
Для блочного внешнего произведения распределение блоков по процессорам будет выглядеть следующим образом:
Для простоты будем считать, что матрицы А и В имеют размерность n´n, n=sm, где s - число блоков, m - число строк (столбцов) в блоке. Далее, пусть множение двух чисел происходит за время Tmul, пересылка одного числа - за время Tsend.
Процесс вычисления состоит из трех этапов:
вычисление произведения блоков;
пересылка результата.
Пусть t1(n) - время множения матриц на одном процессоре, tp(n) - время множения матриц в системе из p = s2 процессоров.
В случае последовательного алгоритма произведение матриц требует n3 операций множения, пересылки данных не требуются.
В случае параллельного алгоритма пересылка исходных данных выполняется за время 2nmTsend, множение блоков - за время m2nTmul, пересылка результата - за время n2Tsend. Тогда
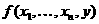

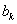
Построим график Sp(n) при p=4 и при различных значениях отношения Tsend/Tmul.

При достаточно больших значениях n
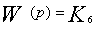
Т.е. получаем линейный прирост производительности при nо¥.
Совсем другая картина получается, если строить строить график Sp(n) как функции от р при некотором фиксированном значении n. В этом случае Sp(n) сначала резко возрастает до некоторого экстремального значения SТ=SpТ(n), затем начинает плавно бывать. Т.е. мы достигли некоторого оптимального значения числа процессоров pТ и дальнейшее величение числа процессоров будет приводить только к замедлению программы. Это объясняется тем, что при величении числа процессоров величивается и объем передаваемых данных.
Значение pТ в данном конкретном случае несложно вычислить. Оно находится из равнения
 p ³
1
p ³
1
Решая равнение,
получим 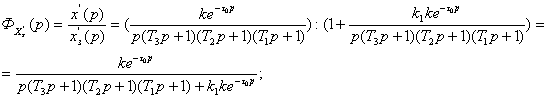 p=pТ максимум эффективности Ep
скорее всего не будет достигнут.
p=pТ максимум эффективности Ep
скорее всего не будет достигнут.

Результаты эксперимента
n
t1(n), сек
tp(n), p=2, сек
Sp(n)
1
1069,195
571,646
1,870
1100
1081,161
784,325
1,378
1200
1870,029
987,869
1,893
1300
2367,853
1293,355
1,831
1400
2966,311
1618,987
1,832
1500
3647,515
1,783
1,824
1600
5011,064
2812,082
1,782
1.3. матриц
Пусть матрица А имеет блочно-диагональный вид, т.е.
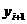
где Аii - квадратная матрица.
Очевидно, что Аn можно вычислить следующим образом
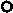
Тогда вполне естественно приписать каждый блок отдельному процессору. При этом, если размерности блоков сильно отличаются, возникает проблема балансировки нагрузки.Данную проблему можно разрешить при помощи динамического распределения блоков между процессами.
Пусть все Аii - матрицы размерности m´m, тогда в системе из p=s процессоров
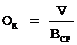

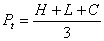
Положим p=4, m=10 и построим график Sp(n) при различных значениях отношения Tsend/Tmul.

Видно, что рост производительности параллельной системы наблюдается как при больших значениях m, так и при больших значениях n.
Вычислим оптимальное число процессоров pТа и построим график Sp(n,m) при n=5, m=10.
Значение pТ определяется из равнения
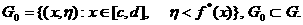 , p ³
1
, p ³
1
Отсюда 

Результаты эксперимента
m
t1(n,m), сек
tp(n,m), p=2, сек
Sp(n)
1
2131,162
1097,971
1,941
1100
2235,178
1142,729
1,956
1200
3764,320
1931,411
1,949
1300
4898,564
2506,942
1,954
1.4. Ленточные матрицы
Матрица А порядка n называется ленточной, если
aij = 0, i - j > b1, j - i > b2
Далее будем рассматривать лишь матрицы с симметричной лентой, для которых b1 = b2 = b. Таким образом, ненулевые элементы матрицы расположены только на главной диагонали и на 2b диагоналях, прилегающих к главной сверху и снизу.
Заметим, что если полуширина ленты для А равна a, для В равна b, то полуширина ленты для АВ в общем случае будет равна a+b.
Пусть А - матрица размерности n´n с полушириной ленты a, В Ч матрица размерности n´n с полушириной ленты a.
Причем А разбита на 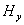 аблоков
аблоков

Число ненулевых элементов матрицы B не превышает (2a+1)n, в блоке Ai Ч (2a+1)m. В результирующей матрице будет не более (4a+1)n ненулевых элементов.
В системе из p процессоров построим вычисление по следующей схеме: первый процессор вычисляет А1В, второй - А2В и т.д. Соответственно, матрицу А выгодно хранить по строкам, а матрицу В - по столбцам. В результате множения получим матрицу, которая будет храниться в памяти по строкам.
На вычисление одного ненулевого элемента матрицы АВ затрачивается время не более (2a + 1)Tmul. Тогда
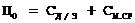
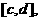
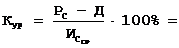
Видно, что ускорение Sp зависит от полуширины ленты a и не зависит от n.

Теперь вычислим оптимальное значение числа процессоров pТ и построим график функции Sp(a) при a=500.
Значение pТ определяется из равнения

Отсюда 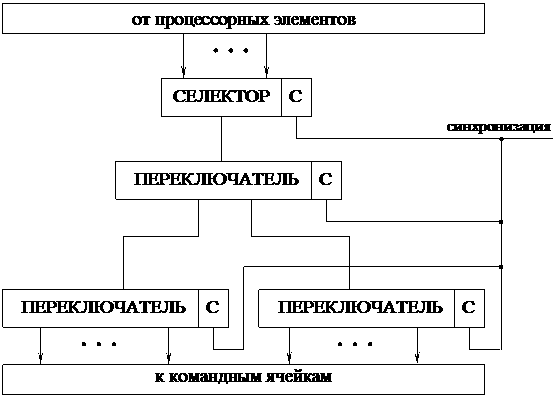

Г Л А В 2
ПРЯМЫЕ МЕТОДЫ РЕШЕНИЯ ЛИНЕЙНЫХ СИСТЕМ
Рассмотрим систему линейных уравнений
Ax = b
с невырожденной матрицей А размера n´n.
2.1. LU-разложение
Постановка задачи
Построим разложение мтрицы A = LU, где L - нижнетреугольная матрица с единицами на главной диагонали, U - верхнетреугольная матрица.
В качестве алгоритма LU-разложения выберем kij-форму с выбором главного элемента по строке (столбцу). прощенно алгоритм можно записать следующим образом
для k = 1 до n-1
для i = k+1 до n
lik = aik/akk
для j = k+1 до n
aij = aij - likakj
Распараллеливание и оценки производительности
Предположим вначале, что система состоит из p = n процессоров. Тогда один из возможных вариантов организации LU-разложения выглядит так. Пусть i-ая строка матрицы А хранится в процессоре i. На первом шаге первая строка рассылается всем процессорам, после чего вычисления
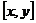 (*)
(*)
могут выполняться параллельно процессорами Р2, Е, Pn. На втором шаге вторая строка приведенной матрицы рассылается из процессора P2 процессорам P3, Е,Pn, и т. д.
На k-ом шаге процессоры P1, Е,Pk-1 простаивают, Pk выполняет нормировку и рассылку строки, Pk+1, Е, Pn - вычисляют по формуле (*). Рассылка строки выполняется з время (n-k)(n-k)Tsend, нормировка - за время (n-k)Tmul. Параллельная модификация строк выполняется за время (n-k)Tmul. Таким образом
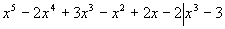

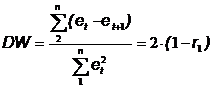
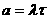
Т.е. при больших значениях n параллельная версия может работать медленнее последовательной версии. Это объясняется значительным объемом обмена данными между каждыми двумя шагами и уменьшением числа активных процессоров на 1 на каждом шаге.
В ситуации, когда p << n, проблема балансировки нагрузки в определенной степени смягчается. Будем считать, что n = mp, и строки 1, p+1, 2p+1, Е хранятся в процессоре 1, строки 2, p+2, 2p+2, Е - в процессоре 2, и т.д. Такой способ хранения называется циклической слоистой схемой.
Для меньшения простоя процессоров будем использовать опережающую рассылку: на k-м шаге (k+1)-я строка рассылается сразу после того, как окончится ее модификация.
Для обеспечения численной стойчивости алгоритма применим схему выбора главного элемента по строке.
В этом случае получим
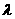
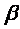
При достаточно больших значениях n
альтернативой для хранения элементов по строкам является столбцовая циклическая схема хранения. В этом случае по процессорам распределяются не строки, столбцы, что позволяет меньшить объем передаваемых данных. Главный элемент будем выбирать в активном столбце.
На k-м шаге процессор, хранящий k-й столбец, выбирает главный элемент, вычисляет значения  i > k) и пересылает их на остальные процессоры. Далее каждый процессор вычисляет по формуле
i > k) и пересылает их на остальные процессоры. Далее каждый процессор вычисляет по формуле


Передача данных происходит за время p(n-k)Tsend, вычисления - за время
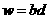 . Тогда
. Тогда
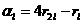
При достаточно больших значениях n
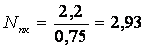
Зафиксируем p=4 и построим графики функции Sp(n) при различных значениях отношения Tsend/Tmul.

Вычислим оптимальное число процессоров pТ и построим график функции Sp(n) при n=5.
Значение pТ найдем из равнения
 p ³
1
p ³
1
Отсюда получаем 

Результаты эксперимента
n
t1(n), сек
tp(n), p=2, сек
Sp(n)
1
450,975
309,948
1,455
1100
600,691
408,078
1,472
1200
780,679
554,960
1,408
1300
993,420
689,396
1,441
2.2. Решение треугольных систем
Постановка задачи
После выполнения LU-разложения нужно решать треугольные системы.
Ly = b, Ux = y
Процесс их решения назывантся прямой и обратной подстановками. Рассмотрим только решение нижнетреугольной системы (решение верхнетреугольной системы организуется аналогичным образом).
В качестве алгоритма решения выберем алгоритм скалярных произведений. Его запись на псевдокоде выглядит следующим образом
для i = 1 до n
для j = 1 до i-1
bi = bi Ц Lijyj
yi = bi/Lii
Распараллеливание
Пусть вычислительная система состоит из p процессоров, размерность матрицы L равна n. Разобьем матрицу L на блоки в соответствии с рисунком

Все блоки
(кроме, может быть, двух последних) состоят из 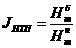 p блоков разбиваются вектора
y и b.
p блоков разбиваются вектора
y и b.
Далее, пусть блок S1 расположен в памяти процессора P1, блоки L2 и S2 - в памяти процессора P2 и т.д. Перед началом вычислений блок bk пересылается процессору Pk, k = 1..p.
Рассмотрим первый шаг алгоритма решения системы.
1. Процессор P1 решает систему S1y1=b1
2. Найденный вектор y1 пересылается процессорам P2, Е, Pp
3. Процессор Pk (k=2..p) пересчитывает вектор bk по формуле
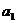
Остальные шаги алгоритма организуются аналогично.
Оценки производительности
Будем считать, что матрица L же распределена по процессорам. В противном случае выгоднее решать систему последовательным способом.
На одном процессоре задача размерности n решается за время

Оценим время выполнения k-ой итерации в системе из p процессоров
Тогда



Зафиксируем p=4 и построим графики функции Sp(n) при различных значениях отношения Tsend/Tmul.

Вычислим оптимальное число процессоров pТ и построим график функции Sp(n) при n=1500.
Значение pТ найдем из равнения
 p ³
1
p ³
1
Отсюда получаем

Результаты эксперимента
К сожалению, для данной задачи не далось получить приемлимых результатов. Дело в том, что на момент проведения экспериментов в сети было недостаточное количество компьютеров, поэтому параллельный алгоритм выполнялся даже дольше, чем последовательный.
2.3. QR-разложение
Постановка задачи
Рассмотрим ортогональное приведение матрицы A
A = QR
где Q Чортогональная, R - верхнетреугольная матрицы. В качестве алгоритма решения задачи выберем преобразование Хаусхолдера. На последовательных компьютерах преобразование Хаусхолдера выполняется примерно в два раза медленне, чем LU-разложение. Поэтому данный метод редко используется для решения СЛУ, однако он широко используется при вычислении собственных значений.
Пусть A - матрица n´n. Рассмотрим запись алгоритма на псевдокоде
для k = 1 до n-1
 ,
, 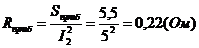
uTk = (0, Е, 0, akk Ц sk, ak+1,k, Е, ank)
akk = sk
для j = k+1 до n
aj = gkukaj, aj = aj - ajuk
Распараллеливание
Первый шаг алгоритма выглядит следующим образом
1. А всем процессорам
2. s1 в процессоре 1 и переслать его всем процессорам.
3. А во всех процессорах в соответствии с алгоритмом Хаусхолдера.
Остальные шаги организуются аналогичным образом.
Оценки производительности
Пусть А - матрица размерности n´n. И пусть система состоит из p процессоров, причем n=pm.
Распределим матрицу А по процессорам в соответствии со столбцовой циклической схемой хранения.
Последовательный алгоритм выполняется за время
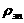
Пересылка начальных данных выполняется за время n2Tsend, пересылка результата Ч за время n2Tsend. Поэтому
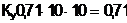
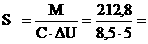

Зафиксируем p=4 и построим графики функции Sp(n) при различных значениях отношения Tsend/Tmul.

Построим график функции Sp(n) при n=2.

Результаты эксперимента
n
t1(n), сек
tp(n), p=2, сек
Sp(n)
1300
1787,780
1406,593
1,271
1400
2242,265
1719,528
1,304
1500
2762,694
2126,785
1,299
1600
4085,485
2969,102
1,376
Г Л А В 3
ИТЕРАЦИОННЫЕ МЕТОДЫ РЕШЕНИЯ ЛИНЕЙНЫХ РАВНЕНИЙ
3.1. Метод Якоби
Постановка задачи
Пусть А - невырожденная матрица n´n и нужно решить систему
Ax = b,
где диагональные элементы aii матрицы А ненулевые. Тогда метод Якоби в матричной форме имеет вид
xk+1 = Hxk + d, k = 0, 1, Е, H = D-1B, d = D-1b,
где D = diag(a11, Е, ann), B = D - A и казано начальное значение х0.
Конечно, метод Якоби сходится не всегда. Приведем две стандартные теоремы сходимости.
Теорема. Если матрица А имеет строгое диагональное преобладание или является неприводимой с диагональным преобладанием, то итерации метода Якоби сходятся при любом начальном приближении х0.
Теорема. Если матрица A = D - B симметрична и положительно определена, то итерации метода Якоби сходятся при любом начальном приближении х0 тогда и только тогда, когда матрица D + B положительно определена.
Для проверки сходимости итерационных приближений будем использовать следующий критерий:


где  .
.
Распараллеливание
Пусть система состоит из р процессоров и матрицы разбиты на блоки следующим образом

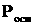 ,
, 
Припишем блоки H1, d1, xk1 процессору Р1, блоки H2, d2, xk2 - процессору Р2 и т.д. Тогда соответствующие компоненты вектора х можно вычислять параллельно по схеме:
Шаг 1. Переслать на i-й процессор Hi, di, x0.
Шаг 2. На к-й итерации i-й процессор выполняет следующие действия:
хiк+1 = Hixik + di
xik+1 остальным процессорам
xk+1
Шаг 3. Если хотябы один флаг не установлен, то перейти к следующей
итерации (Шаг 2).
Шаг 4. Передать результат.
Оценки производительности
Для простоты будем считать, что n = pm. Оценим время выполнения одной итерации метода Якоби.
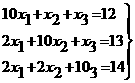

Далее, пусть метод сошелся за k шагов. Тогда
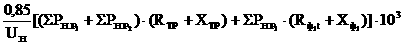
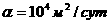
Из последней формулы несложно установить, что если число итераций  , то каким бы большим небыло значение n, нам все равно не дастся достичь ускорения Sp ³
2.
, то каким бы большим небыло значение n, нам все равно не дастся достичь ускорения Sp ³
2.
Зафиксируем p=4, k=500 и построим график функции Sp(n) при различных значениях отношения Tsend/Tmul.

Кривая, которой соответствует значение Tsend/Tmul=1 никогда не поднимется выше 1, т.к. число итераций k слишком мало.
Вычислим оптимальное число процессоров pТ и построим график функции Sp(n,k) при n=5, k=500.
Значение pТ найдем из равнения
 p ³ 1
p ³ 1
Отсюда 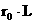 k значение pТ практически не зависит от k (уже при k=100 отношение
k значение pТ практически не зависит от k (уже при k=100 отношение 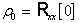 ).
).

Результаты эксперимента
n
t1(n), сек
tp(n), p=2, сек
Sp(n)
1
489,634
,535
1,468
1100
608,457
404,232
1,505
1200
832,035
514,840
1,616
1300
857,569
559,942
1,531
1400
992,017
661,823
1,499
ЗАКЛЮЧЕНИЕ
Результатом данной работы является программная среда FLOWer, предназначенная для конструирования параллельных программ. Основные идеи, включая язык DGL, на которых базируется система, были разработаны самостоятельно.
Для испытания возможностей системы были реализованы некоторые параллельные алгоритмы ВЛА, даны теоретические оценки их эффективности иа проведены вычислительные эксперименты, которые показали состоятельность и эффективность системы.