
 Авторефераты по всем темам >>
Авторефераты по социологии
Авторефераты по всем темам >>
Авторефераты по социологии
Контекстно-ориентированный анализ качественных данных
Автореферат докторской диссертации по социологии
На правах рукописи
Каныгин Геннадий Викторович
КОНТЕКСТНО-ОРИЕНТИРОВАННЫЙ
АНАЛИЗ КАЧЕСТВЕННЫХ ДАННЫХ
Специальность: 22.00.01 Теория, методология и история социологии
Автореферат
диссертации на соискание ученой степени
доктора социологических наук
Санкт-Петербург
2011
Работа выполнена в Учреждении Российской академии наук
Социологический институт РАН
Официальные оппоненты:
доктор социологических наук, профессор
Иванов Дмитрий Владиславович
доктор социологических наук,
Семенова Виктория Владимировна
доктор экономических наук, профессор
Завгородняя Анна Васильевна
Ведущая организация: Государственное образовательное учреждение высшего профессионального образования Российский государственный гуманитарный университет
Защита состоится л25 апреля 2011 г. в 14.30 часов на заседании объединенного диссертационного совета ДМ 002.129.01 при Учреждении Российской академии наук Социологический институт РАН по адресу: 198005, Санкт-Петербург, ул. 7-ая Красноармейская, д. 14/25, в помещении научно-образовательного центра.
С диссертацией можно ознакомиться в библиотеке Учреждения Российской академии наук Социологический институт РАН.
Автореферат разослан л_____ ________________2011 г.
![]() Ученый секретарь
Ученый секретарь
диссертационного совета, к.соц.н.а аа / Бурмыкина О.Н. /
ОБЩАЯ ХАРАКТЕРИСТИКА РАБОТЫ
Актуальность. Анализ качественных данных является одной из областей междисциплинарных исследований, бурно развивающейся в последние три десятилетия как инструментальный аппарат качественной социологии и активно вбирающей в себя методы высоких технологий. Сегодняшний анализ качественных данных - это не только оригинальные методики работы с нечисловой информацией, но и мощная инновационная отрасль производства высокоинтеллектуальных продуктов, включающая в себя решение проблем социальной методологии, разработку программных средств, обучение пользователей, маркетинг и распространение произведенных программ. Уровень развитости компьютерных средств анализа качественных данных рассматривается в современной социальной методологии как показатель ее собственного развития.
Постоянный рост количества исследовательских методов, основанных на анализе нечисловой информации, равно как и быстрое увеличение их применнений в прикладных исследованиях показывает высокую степень востребонванности этого направления в современных социальных науках и областях их практического применения.
Важность разработки новых подходов к анализу качественных данных обунсловлена тем, что именно в этом виде существует социальная информация, получаемая из различных источников и используемая как в целях развития научного знания, так и социального управления. В числе этих источников Ц законодательные акты, свидетельства очевидцев, социологические анкеты, телевизионные трансляции, публичные выступления, мнения граждан и т.д.
В то же время использование нечисловой информации при выражении и сонгласовании взглядов социальных субъектов связано как с практическими, так и с теоретическими трудностями. На практике возникающие проблемы пронявляются в виде разночтений в формулировках документов, служащих инструментами социального управления. В области социальной методологии одной из фундаментальных научных проблем является многонзначность интерпретаций и контекстная обусловленность артикулируемых теоретических положений.
Трудно переоценить актуальность разработки эффективных научных метондов, позволяющих моделировать и устранять указанные разночтения в разнличных фазах их развития: в процессе разработки научной концепции, при формулировании позиций законодателей, интерпретации законов местными органами управления, выполнении нормативных актов населением, судебных разбирательствах, спорах производителей и потребителей по поводу качества товаров и услуг и т.п.
Анализ качественных данных (далее как синоним - изучение нечисловой информации) является предметной областью, чьи методы и компьютерные инструменты в условиях существования многочисленных ветвей современной качественной методологии - этнометодологии, этнографического ананлиза, биографических исследований, дискурсного метода, grounded theory и др. используются социологом с целями выявления и аналитического преодоления многозначности интерпретаций и оценок социальных явлений.
Актуальность диссертационной работы определяется необходимостью разработки инновационных методов анализа нечисловой информации, позволяющих решать проблемы контекстной обусловленности и многозначности аналитических процедур качественного исследования на основе принципов поддержания тождественности социологических понятий в разнообразных теоретических контекстах.
Проблемой исследования является наличие несоответствия между структурным аппаратом анализа нечисловых данных и научными принципами построения аналитических процедур качественного исследования, в том числе: выполнения закона тождества аналитических высказываний, учета теоретического контекста, устранения смысловой многозначности. Индикатором существования проблемы несоответствия выступает отсутствие в составе методов анализа качественных данных критериев, позволяющих аналитически оценивать концептуальные построения, выполненные на основе качественных стратегий.
Степень изученности проблемы. В основе анализа качественных данных как одного из направлений социальной методологии лежит идея дополнения количественных методов конструктивными техниками, возникшими в русле качественных подходов. В отечественной методологической традиции различные идеи и методы количественной парадигмы наиболее полно развиты в терминах социологического измерения и надежности данных. В ряде случаев эти подходы нашли свое выражение в виде компьютерных программ.
Методологические проблемы социологического измерения, его аналитические процедуры, а также их критика раскрыты в работах Ф.М. Бородкина, А.С. Готлиб, А.А. Давыдова, Б.З. Докторова, Ю.Н. Гаврильца, В.Б. Голофаста, И.И. Елисеевой, Т.И. Заславской, М.С. Косолапова, Г.И. Саганенко, В.В. Семеновой, В.Т. Перекреста, В.О. Рукавишникова, Г.Г. Татаровой, Ю.Н. Толстовой, В.А. Ядова и др.
Одна из наиболее совершенных программных реализаций средств и методов количественного исследования создана под руководством В.Т. Перекреста и Т.В. Хачатуровой в виде пакетов программ анализа социально-экономических данных. Принципиально важным ядром этих программ послужили модели метрического шкалирования, предложенные В.Т. Перекрестом. Участие в этих исследованиях позволило диссертанту оценить принципиальную важность доведения измерительных процедур в социологии до стадии компьютерного воплощения, дающего возможность их проверки и дальнейшего совершенствования на основе коллективного использования в прикладных исследованиях.
Конструктивная критика основ количественных методов в социологии содержится в работах С.В. Чеснокова, предложившего методы детерминационного анализа, основанного на идеях поименования как средства измерения в социологии. Знакомство с компьютерной версией этих методов в виде ДА-системы позволило диссертанту оценить возможности развития номинальных измерений как сугубо социологических процедур.
Методологические подходы, альтернативные позитивистски ориентированной парадигме, в том числе когнитивные, социолингвистические, дискурсные, продемонстрированные в трудах Г.С. Батыгина и его учеников Д.М. Рогозина, М.В. Рассохиной и др., позволили оценить общий спектр направлений непозитивистской методологии. Анализ роли текста в качестве конструктивного средства построения социальных теорий, осуществленный Г.С. Батыгиным в его последних работах, убедительно показал фундаментальную важность разработки конструктивных средств выражения альтернативных подходов.
В современной социальной методологии наряду с анализом качественных данных широкое применение находят компьютерные методы обработки текстов, основанные на идеях контент-анализа. В отечественном исследовательском поле подобные методологические решения развивают Г.И. Саганенко и Е.А. Каневский с сотрудниками в виде программной системы ВЕГА. Знакомство с этой разработкой позволило диссертанту увидеть необходимость развития аналитического аппарата, позволяющего концептуализировать наряду с текстовой информацией, также и качественные данные других форматов.
Сравнение предложений Ю.Н. Толстовой по развитию методологии анализа социологических данных, построенных на классических идеях признакового пространства, с аналитическими возможностями современного компьютерного ассистирования в качественном исследовании показало актуальность совершенствования последнего в двух направлениях. Во-первых, создания специального аппарата, ассистирующего исследователю при работе с понятиями на той фазе их разработки, когда они еще не обрели вид эмпирических показателей или переменных с операциональными свойствами. Во-вторых, внедрения в теорию и практику анализа социологических данных методов и соответствующей им терминологии, нашедших широкое применение в системах управления базами данных общенаучного назначения.
Исследования Г.Г. Татаровой в области типологического анализа социологической информации способствовали пониманию роли инструментальных средств качественного исследования, ориентированных на его гуманитарную проблематику и взвешенно использующих естественный язык при развитии социологических методов.
Анализ взглядов А.С. Готлиб продемонстрировал диссертанту необходимость совершенствования конструктивного аппарата качественной методологии с учетом познавательных и экзистенциальных возможностей ее развития. Особенно, в части создания аналитических критериев, оценивающих исследовательские процедуры качественного исследования.
Изучение общих стратегий социологического исследования, проанализированных В.А. Ядовым, и особенностей качественной методологии, раскрытых в работах В.В. Семеновой, дало возможность увидеть необходимость обращения в контексте социальной методологии к методами управления знаниями. Целью такого обращения является конструктивное определение общезначимых социологических понятий, например, социального факта, в условиях существования методологических течений - grounded theory, этнометодологии, дискурсного анализа и др., различающихся по своим интуитивным основаниям, аналитическим процедурам, традициям применения и т.п.
Исследования Д.В. Ивановым процессов виртуализации общественных отношений дали возможность увидеть неожиданные каналы проникновения информационных идей и методов в область социальной методологии.
Знакомство с работами А.Н. Алексеева, С.А. Белановского, Я.И. Гилинского, А.С. Готлиб, В.И. Ильина, Н.Ф. Наумовой, В.В. Семеновой и др. авторов позволило понять методологическое своеобразие как мотивов качественного исследования, так и его отдельных аналитических процедур - формирования выборки, доказательства выводов, включенного наблюдения и др.
В контексте мировой социальной методологии диссертационное исследование, с одной стороны, соотносится с различными направлениями ее непозитивистского развития, в частности, grounded theory, особенно, в ее конструктивистской ветви. С другой стороны, - анализирует и развивает методы изучения нечисловой информации, принципиально дополняющие возможности количественного исследования. Разработкой этих методов на основе соответствующих компьютерных программ занимаются исследователи разных стран.
В 1967 г. Б. Глэйзер (B. Glaser) и А. Страусс (A. Strauss) предложили новую методологическую концепцию, получившую название grounded theory и имеющую своей целью критическое переосмысление традиционных посылок количественного исследования. Дальнейшее развитие grounded theory во многом питалось дискуссиями, инициированными расхождениями во взглядах самих авторов концепции. С одной стороны, Б. Глэйзер, с другой, - А. Страусс и Дж. Корбин (J. Corbin), по-своему поясняли ключевые положения grounded theory - методологию сравнений, способы верификации теории, функции данных и др. Расхождения во взглядах основателей теории создали почву для многочисленных методологических исследований, выполненных такими авторами как: П. Бьернакки (P. Biernacki), Г. Бонд (G. Bond), С. Шениц (C. Chenitz), Н. Денцин (N. Denzin), Е. Губа (E. Guba), Дж. Джонсон (J. Johnson), И. Линкольн (Y. Lincoln), Дж. Морзе (J. Morse), Л. Ричардсон (L. Richardson), Л. Шацман (L. Schatzman), М. Свансон (M. Swanson), С. Винер (C. Wiener) и другие.
Анализ положений grounded theory (идея постоянных сравнений, лежащих в основе теоретизирования, формирование выборки в процессе теоретической работы, роль данных при анализе фактов и ряд других) позволил лучше понять соотношение конструктивных и неконструктивных решений в области социальной методологии, значение формализации в конструктивных подходах, трудности преодоления позитивистской ориентации исследовательских методов и т.д.
Конструктивистское направление grounded theory, развернуто изложенное в работах К. Чармас (K. Charmaz), с одной стороны, строится на стремлении отмежеваться от позитивистских посылок начального этапа развития grounded theory, с другой, соотносится с символическим интеракционизмом Г. Блумера (H. Blumer), искавшего решение проблем обоснованности концептуальных представлений в процессе межличностной коммуникации.
В исследованиях К. Чармас предложено дальнейшее развитие grounded theory на основе симбиоза объективистских и конструктивистских методов, активно использующих приемы кодирования текстовых свидетельств информантов. Изучение взглядов К. Чармас показало, что в части своего конструктивного построения конструктивистская методология заимствует аппарат анализа качественных данных, не предлагая собственных структурных методов. Однако большую эвристическую ценность имеет ряд положений, которые могут быть использованы для целей совершенствования инструментальных средств анализа качественных данных. К их числу относятся: необходимость учета контекстов высказываний информантов; прослеживание умолчаний, без которых невозможно понять смысл свидетельств; стремление иметь средства самоидентификации участников качественного исследования; желание обладать выверенным методологическим аппаратом, с помощью которого акторы формируют социальную реальность и др.
Сегодняшний анализ нечисловой информации существует на основе множества компьютерных программ. В их число входят: AnSWR, AQUAD, Atlas.ti, Decision Explorer, Ethnograph, HyperResearch, Kwalitan, MAXqda, NVivo, QDA Miner, Qualrus, TextQuest, XSight, и др. Различные проблемы развития компьютерных методов качественного исследования рассматриваются в работах многих западных авторов, среди них: П. Аткинсон (P. Atkinson), Х. Беккер (H. Becker), Е. Брент (E. Brent), Е. Вейцман (E. Weitzman), Г. Гиббс (G. Gibbs), Е. Герсон (E. Gerson), К. Драсс (K. Drass), Дж. Зайдель (J. Seidel), У. Келле (U. Kelle), А. Коффи (A. Coffey), Р. Ли (R. Lee), М. Лонкила (M. Lonkila), А. Льюинс (A. Lewins), М. Майлс (M. Miles), Т. Мур (T. Muhr), Б. Пфафенбергер (B. Pfaffenberger), С. Рагин (C. Ragin), Л. Ричардс (L. Richards), Т. Ричардс (T. Richards), С. Сил (C. Seale), Р. Теш (R. Tesch), Н. Филдинг (N. Fielding), М. Фишер (M. Fischer), Б. Холбрук (B. Holbrook), А. Хьюберман (A. Huberman) и др.
Знакомство с указанными программами, а также изучение позиций их разработчиков и пользователей позволило сделать вывод о перспективности совершенствования метафоры современного компьютерного ассистирования в области качественных социологических исследований.
Для развития контекстно-ориентированного подхода, предложенного диссертантом, особое значение имеет ряд методологических позиций, высказанных отдельными авторами. Положение С. Садмена (S. Sudmen) и Н. Бредберна (N. Bradburn), относящееся к методологии анкетирования и рассматривающее любой анкетный вопрос в виде совокупности двух частей - открытой и закрытой. Положение С.В. Чеснокова об эйдическом характере понятий, т.е. необходимости выполнения для них закона тождества. Анализ особенностей текста в качестве конструктивного инструмента создания социальных теорий, проведенный Г.С. Батыгиным и показавший проблематичность выполнения закона тождества понятий в условиях вербального теоретизирования. Тезис В.А. Якобсона о наличии большого контекста, выражение которого затруднено при концептуализации текстов, использующей идею формального семантического языка и предлагаемой в работах Г.В. Лезина, В.А. Тузова и соавторов.
Анализ качественных данных (АКД) - это набор аналитических процедур, выполняемых исследователем в социологическом исследовании при изучении материалов, существующих в текстовом, графическом или ином нечисловом виде с помощью специальных функций кодирования и реконструирования данных (coding and retrieval functions). При своем зарождении эти аналитические процедуры - кодирование фрагментов свидетельств, упорядочиванние кодов, обращение с их помощью к анализируемым материалам и др., практиковались на данных, представленных, по преимуществу, в виде текнстов, и выполнялись с помощью карандаша и бумаги.
Современный анализ качественных данных берет свое начало от ряда незавинсимых научных инициатив, при выполнении которых в 70-80-ые годы проншлого века упомянутые приемы были смоделированы в виде специфических компьютерных программ. Возникшую таким образом предметную область Н. Филдинг и Р. Ли в 1991 году предложили назвать Computer Assisted Qualitaнtive Data AnalysiS (CAQDAS), т.е. анализ качественных данных с помощью компьютерных средств.
На сегодняшний день компьютерные программы (пакеты) анализа каченственных данных нашли широкое применение в практике качественного исследования. Достоинством этих компьютерных инструментов является возможность применять с их помощью качественные методики на больших объемах нечисловой информации. Дополнительным плюсом оказывается возможность использовать различные достижения сонвременного компьютерного ассистирования - новые форматы данных, спонсобы их визуализации, пользовательские сервисы работы с данными, коммунникационные ресурсы и т.д. для целей повышения эффективности работы с качественной информацией.
Однако сегодняшнее развитие программ АКД сонпровождается обоснованной критикой, показывающей, что компьютерные методы не стали полноценным научным инструментом качественного исслендования. Ключевая методологическая проблема анализа нечисловой инфорнмации - многозначность и контекстная обусловленность свидетельств иннформантов - упомянута, например, в работах У. Келле (U. Kelle) лишь в качестве общенаучного фона, на котором компьютерное аснсистирование развивается на основе собственных принципов.
Современное развитие компьютерного ассистирования в АКД проходит не путем создания специальных методов, решающих какую-то специфическую научную проблему, актуальную в гуманитарных дисциплинах, а через наращивание средств, обслуживающих исходную инстнрументальную идею - кодирования данных и сопоставления их фрагментов. Таким образом, главный ресурс развития сегодняшнего компьютерного ассинстирования в качественном исследовании - это современные высокие технонлогии, предоставляющие в арсенал разработчика программ разнообразные компьютерные инструменты общенаучного назначения, которые последний делает доступными для социологов, занимающихся прикладными исследованниями.
Показательно, что за 2004-2006 гг. на одном из ведущих мировых форумов по вопросам качественного исследования и его компьютерной поддержки, созданном при Сюррейском университете ( Стремясь учесть критику со стороны социологов, разработчики компьютернных пакетов стараются рассматривать возможности своих программ в терминнах различных социальных методологий. Например, Дж. Зейдель (J. Seidel) видит программу Ethnograph как инструмент, ассистирующий при выполненнии лобщенаучных действий - наблюдения, лобобщения и размышленния (noticing, collecting, thinking). А. Куккарц (A. Kukartz) и У. Куккарц (U. Kukartz) считают, что их пакет MAXqda построен на веберовском преднставлении об идеальном типе. С точки зрения Г. Хубера (H. Huber), пакет AQAUD призван выразить взгляды К. Поппера (K. Popper), перенесенные в контекст качественного исследования.
Однако следует заметить, что как критика компьютерных программ со стонроны социолога, так и интерпретация функций этих программ в терминах сонциальной методологии носят вербальный характер. Другими словами, недоснтаточно внимательно оценивается роль структур самого анализа качественнных данных, которые воспроизводятся как в составе компьютерных методов, так и социологических методик. Неисследованной оказывается перспектива структурного совершенствования методов кодирования нечисловой инфорнмации, возникших еще в эпоху карандаша и бумаги, но по-прежнему ленжащих в основе компьютерных инструментов ее изучения. Введение кодов, их связывание между собой, обоснование кодов через фрагментирование свидетельств информанта и т.п. являются простыми и наглядными приемами оперирования с нечисловой информацией в качественном исследовании. Эти приемы справедливо рассматриваются в современной социальной методолонгии как сугубо инструментальные средства, использование которых подчиннено достижению научных целей социолога.
Такая подчиненная роль техник, развитых в АКД, обусловлена тем, что, признавая их конструктивными методами качественнного исследования, эти техники нельзя считать полноценным научным аппанратом. Методологическое препятствие состоит в том, что научный аппарат - это методы оперирования понятиями, а кодирование при изучении нечислонвой информации лишь отчасти может рассматриваться как инструмент танкого оперирования. В частности, в техниках кодирования слабо представнлены методы структурирования понятий.
Особо следует сказать о проблеме оценки качества качественного исследованния при использовании программ анализа нечисловых данных. В работах многих авторов, в частности, Г. Гиббса (G. Gibbs), А. Коффи (A. Coffey), П. Аткинсона (P. Atkinson), Т. Кёнига (T. Koenig) и др. указывается, что, применняя компьютерное ассистирование при анализе нечисловой информации, ученый должен самостоятельно контролировать корректность анализа даннных на основе собственных критериев, существующих помимо компьютернного инструментария. Тем самым оказывается, что принципиальный вопрос о том, каким образом могут быть созданы критерии кодирования нечисловой информации еще не нашел конструктивного ответа.
В целом, анализ теоретических и методологических подходов, содержащихся в трудах как отечественных, так и зарубежных авторов показал, что, несмотря на значительный интерес к проблемам анализа качественных данных, вопросы контекстной обусловленности социальной информации, во многом определяющие получаемый исследовательский результат, не обрели удовлетворительных теоретических ответов. Проблема неоднозначности и контекстной зависимости свидетельств информантов требует дальнейшего изучения, методологической и методической разработки. В основе такой разработки должен находиться поиск конструктивных решений, которые в соответствие с требованиями современной социальной методологии должны быть воплощены в компьютерные инструменты анализа нечисловой информации.
Объектом исследования служат методы и процедуры анализа качественнных данных. Предметом исследованиявыступает создание новых методологических подходов, позволяющих усовершенствовать функции кодирования и реконструирования нечисловой информации (coding and retrieval functions) в предметной области анализа качественных данных.
Цель и задачи исследования. Целью диссертационного исследования служит создание новых методов, основанных на оперировании научными понятиями и предназначенных для конструктивного решения проблем самоидентификации участников качественного исследования в условиях многозначности и контекстной обусловленности как свидетельств информантов, так и аналитических процедур самого исследования.
Для достижения цели в диссертации поставлены следующие задачи.
- Проанализировать особенности и тенденции развития современных методов анализа качественных данных.
- Сформулировать методологические особенности техник кодирования как аппарата оперирования социологическими понятиями.
- Выполнить анализ возможностей текста в качестве инструмента оперирования социологическими понятиями.
- Выявить методологические запросы социального исследователя, применяющего анализ качественной информации.
- Проанализировать критерии, используемые для оценки качества социологического исследования.
- Выявить структурные особенности техник кодирования как аппарата оперирования социологическими понятиями.
- Сформулировать принципы контекстно-ориентированного анализа качественных данных, позволяющие структурно усовершенствовать функции кодирования и реконструирования данных.
- Разработать структурные основы контекстно-ориентированного анализа качественных данных, позволяющие создать механизм оценивания аналитических построений в составе структурного аппарата контекстно-ориентированного кодирования.
- Создать контекстно-ориентированные методы изучения нечисловой информации, представляющие собой аппарат оперирования социологическими понятиями.
- Спроектировать и создать программный пакет контекстно-ориентированной концептуализации нечисловой информации, включающий в себя инструменты оперирования социологическими понятиями в задачах концептуализации нечисловой информации и инфраструктуру такого оперирования: управление собственными базами данных, организация пользовательских интерфейсов и т.д.
- В составе пакета реализовать инструменты оценивания результатов контекстно-ориентированного кодирования, выполняемого пользователем.
- Продемонстрировать возможности компьютерных контекстно-ориентированных методов на типичных задачах концептуализации нечисловой информации, в том числе практическое применение аппарата оценивания аналитического кодирования свидетельств информанта.
Теоретические и методологические основы исследования. Теоретико-методологическую основу исследования составляют концептуальные положения теоретической социологии, лингвистической философии, герменевтики, этнометодологии, символического интеракционизма, конструктивизма, grounded theory. Компьютерное моделирование контекстно-ориентированного анализа основано на методологии объектно-ориентированного программирования и теории реляционных баз данных.
Основные результаты, определяющие новизну проведенного исследования
- Крупным научным достижением диссертации является создание на основе методологии анализа качественных данных структурного аппарата контекстно-ориентированного кодирования, который позволяет аналитически оценивать концептуальные построения на основе качественных стратегий.
- Сформулированы методологические принципы анализа нечисловых данных, в том числе: оперирование понятиями и явными отношениями между ними, мнемоническое кодирование, прослеживание умолчаний в свидетельствах информантов, структурный учет контекстов высказываний.
- Выявлены структурные недостатки функций кодирования в анализе нечисловой информации, не позволяющие квалифицировать эту методологию качественного исследования как аппарат оперирования социологическими понятиями.
- Выполнено структурное совершенствование функций кодирования в анализе качественных данных, состоящее в разработке, во-первых, представления об аналитическом коде, выражающим собой конструктивные свойства социологических понятий, характеризующие их до прохождения процедуры операционализации. Во-вторых, универсального структурного отношения между аналитическими кодами, представляющего собой модель их локального контекстно-зависимого изменения.
- Разработаны приемы контекстно-ориентированного кодирования нечисловой информации, являющиеся техниками введения аналитических кодов и универсальных структурных отношений между ними. Результаты контекстно-ориентированного кодирования представлены в виде структурированной системы разъяснений (тезауруса), связывающей в единое целое все аналитические коды, введенные исследователем при анализе нечисловой информации.
- Развиты оригинальные методы анализа контекстно-обусловленных отношений между исследовательскими понятиями, позволяющие выполнять алгоритмически проверяемый учет контекстов введения исследовательских представлений, выражать умолчания, предъявлять индивидуальные позиции и т.п. В число впервые предложенных методов входят: человеко-машинная разработка тезауруса многозначных понятий, средства разбиения аналитических обозначений на смысловые области (иерархия контекстов), инструменты агрегирования контекстно-зависимых аналитических суждений (терминологический граф) и др.
- Предложены аналитические критерии связности анализа нечисловой информации, выполняемого методами контекстно-ориентированного кодирования.
- Создан программный пакет, реализующий контекстно-ориентированные методы в виде компьютерных инструментов анализа нечисловой информации. С помощью пакета продемонстрированы приемы контекстно-ориентированной концептуализации качественных данных при определении понятий, выражении их многозначности, прослеживании умолчаний, учете контекстов использования, аналитическом переформулировании свидетельств информанта и т.п.
- Средствами программного пакета продемонстрировано практическое применение разработанных критериев связности в задачах концептуализации свидетельств информанта.
- Путем создания программного пакета доказана конструктивная реализуемость теоретически разработанного анализа качественных данных.
Положения, выносимые на защиту
- Проблема критериев качества аналитических методов является одной из нерешенных в современной методологии качественного социологического исследования. Эта проблема может быть решена путем совершенствования структурного аппарата анализа нечисловой информации, представленного функциями кодирования и реконструирования данных.
- Совершенствование функций кодирования должно исходить из методических требований, обусловленных их использованием в прикладном качественном исследовании: прослеживания умолчаний и неявных смыслов высказываний информантов, учета многозначности и контекстной обусловленности как суждений информантов, так и аналитических процедур самого исследователя, поддержания тождественности понятий в различных аналитических контекстах.
- Предложено конструктивное совершенствование функций кодирования, осуществленное путем разработки аналитического аппарата контекстно-ориентированного кодирования. В составе этого аппарата в виде отдельных структурных моделей включены такие составляющие качественных методов, как: социологическое понятие, используемое при операциях поименования до стадии операционализации; отношение между социологическими понятиями как модель их контекстно-зависимого изменения; результаты кодирования в виде совокупности понятий и явных контекстно-обусловленных отношений между ними (тезаурус), инструменты анализа тезауруса.
- Указанные структурные модели позволили разработать методы контекстно-ориентированного кодирования, которые представляют собой техники использования созданных структурных моделей в задачах концептуализации эмпирических данных.
- Разработанные структурные модели и методы контекстно-ориентированного кодирования выражают собой новую методологию, названную контекстно-ориентированным анализом качественных данных и предложенную автором для решения проблем оперирования социологическими понятиями и явными отношениями между ними в контексте качественного исследования.
- Особое значение для развития средств научной методологии имеет решение проблемы установления явных отношений между исследовательскими понятиями. В составе структур контекстно-ориентированного кодирования предложено решение этой проблемы в виде обоснованного автором отношения между моделями исследовательских понятий, названного контекстно-фиксированным разъяснением. Использование аналитиком контекстно-фиксированного разъяснения при проведении контекстно-ориентированного кодирования позволяет удовлетворить вышеперечисленным методическим требованиям качественного исследования: прослеживания умолчаний, учета многозначности понятий, поддержания их тождественности при использовании в различных контекстах.
- Разработанный контекстно-ориентированный аппарат дал возможность решить проблему аналитического оценивания методик качественного исследования в виде критерия связности результатов контекстно-ориентированного кодирования. Критерий связности входит в состав инструментов анализа исследовательского тезауруса и представляет собой средство аналитического оценивания качественных стратегий.
- Полная конструктивная реализуемость теоретически разработанных контекстно-ориентированных методов концептуализации доказана путем разработки компьютерного пакета, программно моделирующего предложенные методы.
- С помощью пакета продемонстрированы практически работающие конструктивные критерии связности аналитического выражения свидетельств информанта, представленных в текстовом виде.
Теоретическая и практическая значимость. Диссертация вносит вклад в решение теоретических проблем разработки научного аппарата оперирования исследовательскими понятиями и явными отношениями между ними в аналитических процедурах качественного исследования.
Предложены модели и алгоритмы контекстно-ориентированного кодирования нечисловой информации, которые развивают инструментальные средства компьютерных методов анализа нечисловой информации на принципах качественной методологии. Разработанный аппарат может быть квалифицирован как конструктивный инструментарий качественного исследования. Контекстно-ориентированное кодирование представляет собой ряд структурных моделей и методов их применения с целью создания и анализа совокупностей поименований, т.е. сугубо социологического механизма образования понятий, работающего в тех ситуациях, например, case-study, когда социологические термины еще не прошли стадию операционализации.
Разработанный аппарат контекстно-ориентированного кодирования позволил предложить теоретическое решение проблемы критериев качества качественного исследования. Это решение существует в виде алгоритмов генерации иерархии контекстов и терминологического графа, представляющих собой инструменты контроля связности аналитических построений социолога в процессе концептуализации нечисловой информации.
Практическая значимость методов определяется эффективностью практики применения компьютерных средств анализа качественных данных как сложившейся мировой методологической дисциплины в ряде отраслей социологических исследований, в том числе: в медицинской социологии, корпоративном управлении и др. Перспективность применения контекстно-ориентированных методов в приложениях такого рода обусловлена неизбежным следствием контроля связности концептуализации, предложенного в диссертации. По своей природе предложенные методы оценивания не требуют обязательного обращения к эксперту, который неизбежно приносит в каждую экспертизу собственное методологическое кредо. Указанный способ концептуального контроля не зависит от аналитика и может быть выполнен любым реципиентом его теоретических рассуждений.
Находясь в условиях возможного автоматического контролирования своих концептуальных построений, аналитик побуждается к более ответственному формулированию собственных утверждений. Это особенно важно в том случае, когда необходимо согласовать терминологический аппарат, используемый разными акторами в процессе социальной коммуникации. Например, в задачах создания управленческих процедур, используемых электронным правительством.
Апробация работы. Результаты диссертации доложены на 5-ой международной конференции по логике и методологии науки (3-6 октября 2000, Кельн) и 6-ой международной конференции по логике и методологии науки (17-20 августа 2004, Амстердам).
Автор неоднократно выступал с докладами на методологическом семинаре Социологического института РАН, научных семинарах ЭМИ РАН и ГОБУ ВПО Государственный университет - Высшая школа экономики. Основные положения контекстно-ориентированного подхода изложены в докладах на XXXVI международной филологической конференции (секция лИнформационные системы в гуманитарных науках) 12-17 марта 2007 г., Санкт-Петербург; социологических чтениях памяти В. Голофаста лСоциология. Вчера, сегодня, завтра 23-25 марта 2007 г. и 3-5 апреля 2008 г., Санкт-Петербург; методологическом семинаре сектора социологии знания Института социологии РАН, май 2007 г., Москва; Методологическом семинара памяти Г.С. Батыгина лПроблемы теории и практики получения первичных данных в социологических исследованиях, 25?26 апреля 2008 г., Москва; конференции Современная социология в поисках новых методологических подходов и методов исследования, 16-17 мая 2008 года, Самарский государственный университет, Самара; XIII Всероссийской объединенной конференции Интернет и современное общество (IMS-2010), 19-21 октября 2010 года, СПбГУ, Санкт-Петербург.
Изложение базовых идей контекстно-ориентированного подхода выполнено на сайте
- Принципы разработки систем компьютерного ассистирования интервьюированию (методология), 2000-2002, РФФИ, №00-06-80184;
- Принципы разработки систем компьютерного ассистирования интервьюированию (программная реализация), 2000-2002, РГНФ, №00-03-00279а;
- Проблема неоднозначности понятий в социологическом исследовании, 2003-2004, РФФИ, №03-06-80273;
- Контекстно-ориентированные методы построения теорий, 2006 Ц2008, РФФИ, 06-06-80237-а.
Основные положения диссертационного исследования изложены в 31 работе общим объемом более 35 п.л., в т.ч. одной монографии по теме диссертации и 26 публикациях, из которых 15 являются статьями в рецензируемых научных журналах.
Структура и объ?м диссертации. Диссертация состоит из введения, шести глав, выводов по каждой главе, заключения, библиографии из 259 источников. Объ?м диссертации - 299 печатных страниц. Во введении сформулированы цели и задачи исследования. В первой главе проанализированы инструментальные начала и методологические особенности анализа качественных данных как конструктивной методологии качественного исследования. Во второй главе раскрыты проблемы и принципы совершенствования методов АКД. В третьей главе изложены методологические основы контекстно-ориентированного АКД. В главе 4 введены структурные модели контекстно-ориентированного АКД. Глава 5 описывает компьютерную реализацию контекстно-ориентированного АКД. В главе 6 продемонстрированы техники применения контекстно-ориентированного кодирования в задаче концептуализации свидетельств информанта.
ОСНОВНОЕ СОДЕРЖАНИЕ РАБОТЫ
Современный анализ качественных данных
Эмпирические данные, рассматриваемые в социальных науках как фактологическая основа исследования, подразделяются на два типа: количественные и качественные. Эти типы различаются операциями, разрешенными со значениями. Для количественных данных такими операциями служат известные количественные действия: сложение, вычитание, умножение и т.д.
Качественные или нечисловые данные могут быть подвергнуты другим операциям: фрагментированию, объединению и связыванию фрагментов, кодированию и т.д. Широко распространенными форматами нечисловых данных являются: текстовый, аудио и видео.
В гуманитарных исследованиях качественные данные появляются из различных источников: полевые заметки социолога, интервью политического деятеля, беседа с информантом, рисунки этнографа и т.п. Один и тот же источник может поставлять данные разных форматов. Например, интервью может быть оформлено в виде текста, аудиофайла или жесткой анкеты, основанной на количественных шкалах.
В отличие от количественной информации нечисловые данные легко интерпретируются людьми, вовлеченными в гуманитарный проект - информантами, аналитиками, заказчиками и т.д. (далее - акторы качественного исследования или просто - акторы), т.к. представляют собой ясный аналог рукописи, речи или рисунка. Однако невозможность выполнения с качественными данными количественных операций, имеющих длительную традицию становления и развития в сфере точных наук, порождает характерные проблемы анализа такого сорта лочевидных свидетельств - обозримости всей совокупности мнений; согласования суждений, найденных в разных источниках; оценки важности отдельных свидетельств и т.п.
Анализ качественных данных (АКД, синоним - изучение нечисловой информации) является одной из предметных областей, в которой исследуются и разрабатываются приемы, методы и методология решения подобных проблем для целей применения в социологическом исследовании. АКД является широко применяемым инструментом качественного социологического исследования. Конструктивной основой такого применения являются специфические операции с качественными данными, которые получили название функций кодирования и реконструирования данных (coding & retrieval functions).
Аппарат кодирования в АКД отличен по своим методологическим посылкам от другой распространенной техники, входящей в состав методов качественного исследования - контент-анализа. Последний строится на идее поиска в тексте ключевых слов, каждое из которых имеет объективный смысл (контент), предполагаемый за ним до начала анализа.
В АКД аналогом ключевого слова является код, смысл которого формируется аналитиком в процессе анализа (текста или собственных построений) и выражается структурой связей, в которую включен код. Эта структура связей создается с помощью функций кодирования и реконструирования данных, имеющих особенности для каждого компьютерного пакета. Для последователя АКД важна, в первую очередь, возможность реконструирования смысла в ходе собственных аналитических построений. За счет такого реконструирования становится возможным переопределять с учетом конкретных условий любого из человеческих суждений смыслы отдельных слов и словосочетаний, идущие от их общеупотребительной языковой практики.
Такой структурно-ориентированный подход, характерный для АКД, позволяет анализировать его методами, в отличие от контент-анализа, не только текстовую информацию, но и другие ее виды, используемые в социальной коммуникации - графическую, звуковую, видеоряд и др. Необходимым условием осуществления такого анализа служит возможность фрагментирования потока информации.
Кодирование. Инструментальный смысл кодирования состоит в разделении анализируемых данных на фрагменты с целью их последующего наглядного соотнесения (рис. 1). Такие фрагменты могут быть, например, сильно разнесены или по разным причинам малозаметны в потоке собранной информации, что является препятствием при ее анализе.
Приемы кодирования не являются продуктом каких-то определенных методологических установок, возникших в рамках конкретной социальной методологии. Эти инструментальные техники оказываются вполне самостоятельным конструктивным аппаратом, который может быть применен в различных теоретических или методологических контекстах.
Кодирование отдельных фрагментов и иерархизация кодов, выполняемые исследователем - основа анализа качественных данных. Каждый текстовый фрагмент выражает контекст введения понятия (кода).
В каждом из таких контекстов функции кодирования сохраняют свое структурное своеобразие, которое характеризуется следующими пунктами:
- Исходной информацией являются качественные данные.
- Данные фрагментируются исследователем (аналитиком) на заранее не оговариваемых основаниях.
- На тех же основаниях аналитиком вводятся аналоги исследовательских понятий - коды.
- Коды соотносятся исследователем с фрагментами данных. Разным кодам могут соответствовать как разные, так и одни и те же фрагменты.
- Фрагмент данных считается контекстом для кода, т.е. формальным описанием тех обстоятельств, в которых вводится код.
- Аналитические процедуры с кодами не оговариваются, исследователь вводит их по собственному усмотрению. Как правило, структурные отношения между кодами устанавливаются в виде списков, древовидных графов и т.п.
Это структурное своеобразие дополняется одним общенаучным методологическим постулатом. Данные рассматриваются как факты, т.е. обосновывают сугубо авторские коды в традиции научного эксперимента - через предъявление связи между наблюдаемым событием, существующим в виде фрагментированного свидетельства информанта, и его описанием, выраженным в виде кода.
Будучи реализованными в программах изучения нечисловой информации, средства кодирования позволяют добиться новых возможностей в работе с данными, среди которых: разбиение бесконечного символьного потока на обозримые фрагменты, иерархизация выделенных фрагментов, организация доступа к отдельным частям неструктурированных данных с помощью вводимых кодов и т.п.
Кодирование является одним из основных инструментов концептуализации информации в качественном исследовании.
Концептуализация в АКД. Инструментально концептуализация выглядит как переход от текста или информации в другой нечисловой форме, выражающей факты, через использование функций кодирования к резюмирующему тексту, в котором представлены результаты анализа исходной информации.
Таким образом, функции кодирования и текст являются основными аналитическими инструментами АКД. В диссертации проанализированы теоретические основания АКД, позволяющие рассматривать его в качестве конструктивной, сугубо непозитивистской методологии качественного исследования. В их числе: относительно простой аналитический аппарат по сравнению с количественными методами; специфическая научная проблема, решаемая с помощью кодирования - многозначность и контекстная неопределенность свидетельств информанта и аналитических процедур исследователя; поиск конструктивной замены базовым представлениям количественного исследования - признаковому пространству, латентным переменным и др.; отстранение от естественного языка в качестве инструмента социального теоретизирования; обращение к свидетельствам информанта для реконструирования их смысла, а не выражения лобъективного содержания.
Эти методологические основы АКД резюмированы как отчетливое стремление качественной методологии создать свой собственный научный аппарат, основанный на операциях с понятиями, а не на вербальных описаниях увиденного. Кодирование - это попытка следовать в гуманитарном дискурсе естественнонаучным методологическим принципам, структурирующим научные построения с помощью понятий и явных отношений между ними.
Принципиально важно, что в результате кодирования в распоряжении исследователя наряду с качественными данными и текстом оказываются новые, построенные им самим аналитические средства - коды. Коды - это аналоги исследовательских понятий, которые возникают на основе языковой практики информанта, но структурируются с помощью операций, задаваемых самим аналитиком.
Научный аппарат АКД ориентирован на решение двойственной задачи. С одной стороны, выражает разнообразные лобъективные жизненные условия, в которых действуют социальные акторы. С другой, - дает возможность реконструировать смысл действий акторов, т.е. выражать чувства, мотивы, намерения и другие, трудно артикулируемые феномены, которые учитываются акторами в своих действиях по изменению лобъективных жизненных условий.
Для решения первой части этой задачи АКД заимствует методы позитивных наук. Собственная научная специфика АКД относится к функциям кодирования как аппарату реконструкции смыслов высказываний и действий информантов. В этой реконструкции аналитик призван основываться не только на рассматриваемых суждениях респондента, но и на большом контексте социального опыта, который неизбежно затрагивается такими суждениями. Важно, что такая реконструкция связывается не с возможностями математического, информационного или иного формального моделирования большого контекста, а с применением человеком инструментальных средств, позволяющих ему переформулировать в непротиворечивом виде нечисловую информацию, полученную в качественном исследовании.
Исходным пунктом такой реконструкции оказывается само введение кода. Переобозначение фрагмента свидетельства информанта подразумевает, что аналитик берет на себя решение принципиально важной научной задачи, состоящей в поддержании тождественности введенного кода во всех аналитических процедурах, выполняемых на основе кодирования.
Именно требование тождественности исследовательских понятий в разнообразных контекстах их использования позволяет считать кодирование инструментом концептуализации нечисловой информации и рассматривать как научный аппарат качественного исследования, а не как вспомогательный прием, позволяющий произвольно манипулировать свидетельствами информанта.
Однако аналитические процедуры качественного исследования еще не обрели законченную форму в виде научного аппарата, выраженного в виде понятий и явных отношений между ними.
В диссертации приводятся два доказательства структурной незавершенности аппарата кодирования. Во-первых, применение текста, с помощью которого аналитические процедуры качественного исследования доводятся до требуемого уровня ясности. Во-вторых, постоянные попытки социологов, использующих аппарат кодирования в практических исследованиях, дополнить инструменты АКД другими приемами, например, категоризацией (К. Чармас, А. Готлиб). Однако отмеченные попытки не могут считаться успешными, т.к. подменяют конструктивные средства АКД вербальными рассуждениями, несущими в себе неопределенность естественного языка.
В современном анализе качественных данных, выполняемом с помощью компьютера, любой пакет наряду с функциями кодирования включает и другие инструменты, воплощающие идеи операционализации исследовательских действий с нечисловой информацией. В их число входят, во-первых, сами качественные данные, представленные, как правило, в виде текста. Во-вторых, вторичные инструменты анализа, надстроенные над качественными данными и функциями кодирования. В одних пакетах ими могут быть атрибуты кодов, в других - средства их визуализации, в-третьих - матрицы связей между кодами и т.д.
Основываясь на мировой практике применения пакетов анализа нечисловой информации, в диссертации подчеркнуто, что ключевая научная проблема преобразования стихии людских мнений в аналитическое изложение фактов решается именно с помощью функций кодирования. Остальные инструменты (поиска, визуализации, статистики кодов и др.), являясь полезными в целом ряде исследовательских ситуаций, остаются вспомогательными ресурсами изучения качественной информации.
Ключевая роль кодирования при создании исследователем аналитического переосмысления свидетельств информантов позволила диссертанту высказать гипотезу, что критерии качества концептуализации и всего анализа нечисловой информации зависят именно от структурного совершенства функций кодирования. Для доказательства данной гипотезы в диссертации, во-первых, рассмотрены существующие взгляды на критерии качества анализа нечисловой информации; во-вторых, путем структурного совершенствования аппарата кодирования построены критерии качества концептуализации нечисловой информации.
Критерии качества концептуализации. В современных социологических исследованиях широко распространены два подхода к оценке качества получаемых исследовательских результатов. Во-первых, обращение к естественнонаучным аналогам, которые строятся на идеях валидности (validity), надежности (reliability) и обобщаемости (generalisability). Валидность предполагает, что результаты концептуализации действительно отражают явления, наблюдаемые посредством данных. Надежность, в частности, триангуляция, предполагает, что результаты, полученные с помощью анализа качественной информации, могут быть повторены различными исследователями. Обобщаемость означает возможность переноса результатов анализа, полученных для отдельных случаев, на более широкую совокупность явлений. Во-вторых, различные критерии прозрачности качественного исследования - постулат адекватности (А. Шюц), правила ответственных высказываний (З. Бауман), подробное и скрупулезное описание аналитических процедур (А. Готлиб) и др.
Однако в качественном исследовании всегда приходится делать оговорку, что эти критерии существуют в условиях большого разнообразия социальных методологий, имеющих свой собственный понятийный аппарат и правила работы с ним. Такие методологические расхождения приводят к тому, что сегодня социологи-качественники вынуждены сверять свои теоретические суждения не по научным критериям, а по рецептам, формулируемым в самом общем виде (А. Готлиб).
Источники совершенствования техник кодирования АКД. Предлагаемые в диссертации оригинальные методы кодирования обоснованы в разноплановых научных контекстах. Во-первых, в рамках методологических особенностей социального исследования, основанного на идеологии конструктивистской grounded theory. Во-вторых, в логике обращения к тексту, используемому в качественном исследовании для решения разнообразных методологических задач: выражения свидетельств информанта, обозначения кодов, предъявления аналитических результатов и т.п. В-третьих, в анализе тенденций развития современных компьютерных программ АКД.
Конструктивистская методология качественного исследования. В диссертации проанализированы теоретические различия между позитивистскими и конструктивистскими взглядами на аналитические процедуры социологического исследования. Особое внимание уделено анализу конкретных приемов изучения свидетельств информантов, основанных на положениях современной конструктивистской grounded theory. Показано, что конструктивное развитие этого методологического направления сдерживается инструментальными возможностями современного аппарата кодирования, который позволяет обозначать и разнопланово сопоставлять свидетельства информантов, но не предоставляет инструментов выражения собственных аналитических процедур - осевого кодирования, категоризации и др.
В диссертации подчеркнута важность развития конструктивной методологии качественного исследования в направлении создания аналитического инструментария, отслеживающего как в свидетельствах информанта, так и в построениях исследователя две их особенности. Во-первых, наличие неявных смыслов и умолчаний. Во-вторых, контекстную обусловленность.
Текстовое теоретизирование. В диссертации проанализированы инструментальные возможности текста в качестве средства, позволяющего решать проблему многозначности и контекстной неопределенности как свидетельств информанта, так и аналитических процедур. Несомненными достоинствами этого медийного ресурса при его использовании для целей концептуализации информации в качественном исследовании являются: возможность применения в любой предметной области, естественность для акторов качественного исследования, поддержка современными информационными технологиями.
В то же время диссертантом обоснованно показано, что одним из существенных недостатков текста в качестве инструмента концептуализации является отсутствие в его структуре специальных средств, ориентированных на работу аналитика с основными элементами научных построений - понятиями. Используя текст в процессе научной коммуникации, каждый актор (исследователь, респондент, информант) вынужден по своему усмотрению решать задачу распознавания смыслов, на которых основана коммуникация. В условиях огромной массы представлений, циркулирующих между акторами при посредничестве текста, трудности их идентификации чреваты большим числом ошибок, вызванных нарушением закона тождества используемых понятий.
Тенденции развития пакетов АКД. В диссертации показано, что компьютерные программы анализа нечисловой информации развиваются как модели инструментальных идей АКД, без учета его особенностей в составе качественных методов. В частности, принципиально важная в социологических проектах проблема многосмысленности и контекстной неопределенности терминов оказывается общенаучным фоном, не имеющим своего структурного оформления в составе пакетов. Также еще не найден отчетливый ответ на другой принципиально важный для качественной методологии вопрос - о возможностях контроля с помощью пакета АКД аналитических процедур качественного исследования.
Современное компьютерное ассистирование в анализе качественных данных развивается путем заимствования информационных достижений (новых форматов данных, методов организации работы пользователей, интернет-технологий и др.) и их адаптации к инструментальным задачам работы с качественными данными.
Критика современных пакетов со стороны практикующих исследователей оказывается малоэффективной, т.к. проводится в таких терминах, как, например, отстраненность исследователя от анализируемых данных, использование количественных методов для анализа качественной информации, обезличенность (homogeneity) исследовательских подходов, и т.п., которые не позволяют понять структурные недостатки функций кодирования, на которых основаны пакеты.
Современные программы, ассистирующие в качественном исследовании, полезны при управлении нечисловыми данными, возникающими при выполнении научного проекта, но не всегда оправдывают методологические ожидания исследователя. Например, в работах современных западных авторов (K. MacMillan, S. McLachlan, G. Gibbs, A. Lewins) отмечается, что пакеты плохо зарекомендовали себя при концептуализации данных, выполняемой для целей дискурсного анализа свидетельств информантов.
В диссертации подчеркивается, что важным, но недооцененным источником развития пакетов АКД в качестве инструмента качественного исследования является структурное совершенствование функций кодирования.
Структурные недостатки функций кодирования. Несмотря на постоянное совершенствование аппарата кодирования, осуществляемое в виде регулярно обновляемых версий соответствующих компьютерных программ, методы АКД постоянно воспроизводят принципиальный структурный недостаток, возникший еще в эпоху карандаша и бумаги. Для структурного выражения важного общенаучного представления о контексте, в котором существует вводимый код, функции кодирования используют текст, т.е. инструмент естественноязыковой коммуникации между акторами.
Контекст определяется как текстовый фрагмент, с которым исследователь связывает код при его создании. Тем самым оказывается принципиально урезанной исходная идея кодирования - переход на оперирование кодами с целью устранения естественноязыковой неопределенности свидетельств информанта.
Проблема особенно отчетливо проявляется в том случае, когда наряду с первичными кодами, переобозначающими свидетельства информанта, аналитик создает вторичные или аналитические коды. Целью введения этих кодов является, как и в случае их первичных аналогов, переформулирование или концептуализация. Однако в ситуации вторичного кодирования переформулируются не свидетельства информанта, а первичные коды, т.е. представления, введенные самим исследователем. Причем вторичное кодирование предполагает не только переформулирование, но и обобщение первичных кодов.
Структурные коллизии, возникающие при таком обобщении, отчетливо видны на примере широко распространенной в качественном исследовании процедуры осевого кодирования. Вторичные коды, возникающие при осевом кодировании, обычно называемые категориями, по смыслу процедуры обобщают первичные коды. При такой процедуре обобщения каждый из первичных кодов осмыслен в структурно определенном контексте, который представляет собой фрагмент текста информанта.
А в каком контексте осмыслена сама категория? Структура функций кодирования не дает ответа на этот вопрос. Непосредственно с текстом информанта категория структурно не связана и не может быть связана, т.к. строится по кодам, т.е. структурам, отсутствующим в кодируемом тексте. Если же рассматривать в качестве контекста для категории совокупность первичных кодов, которые она обобщает, то невозможно структурно установить смысловой контекст категории. Каждый из кодов имеет свой текстовый фрагмент, выражающий его контекстное осмысление.
Отсюда ясно видно направление совершенствования структуры функций кодирования - развитие методов введения и учета контекста в ситуациях аналитического кодирования.
Структурные основы контекстно-ориентированного анализа качественных данных
Функции кодирования, имеющие в качественном социологическом исследовании отчетливо вспомогательный статус, в диссертации развиты до уровня полноценного научного аппарата, построенного на принципах оперирования понятиями (терминами) и явными отношениями между ними. Все конструктивные решения, предлагаемые в диссертации, апробированы путем их моделирования в виде компьютерного пакета, включающего в себя, во-первых, инструменты работы с понятиями, во-вторых, необходимую инфраструктуру такой работы (управление базами данных пакета, пользовательские интерфейсы, традиционные способы ассистирования и т.д.). Иллюстрирующие рисунки (за исключением рис. 2) являются пользовательскими интерфейсами пакета.
Основные определения и структуры. Базовыми инструментами контекстно-ориентированного аппарата кодирования являются, во-первых, три вида аналитических обозначений (дескрипторов) - термин (понятие, неодушевленный объект), актор (одушевленный объект) и действие (ассоциация понятия и актора).
Во-вторых, простейшее в рамках подхода структурное отношение между дескрипторами, названное контекстно-фиксированным разъяснением (КФР). КФР представляет собой обозначение единичного изменения дескрипторов, осуществляемого аналитиком. Моделью изменения является отношение родитель-дети, которое трактуется как преобразование аналитиком дескриптора в положении родитель в набор других дескрипторов, составляющих список детей.
Нотация КФР представлена в виде формулы (1).
t(c):t(p)о{ti},аа (1)
где t(p)о{ti} - структура родитель-дети, каждым элементом которой является термин: t(p) - родитель, а {ti}, i=0,...,n-1 - список детей. t(c) - это термин, с помощью которого обозначено изменение одного понятия на группу других, выраженное отношением родитель-дети. В зависимости от положения термина в структуре КФР t(c) называется контекстом, t(p) - целевым или разъясняемым термином, любой ti - пояснением.
КФР имеет интуитивно ясную интерпретацию. Например, проводя в 2004 г. опрос, социолог обращается к представлению о социально-демографических характеристиках опрашиваемых. Развиваемый подход требует, чтобы исследователь обязательно указал, в каких условиях, иначе говоря, относительно какого контекста, сформировано его суждение. С учетом возможных для данного случая интуитивно понятных дескрипторов (1) может получить вид (2):
оПОЛ, ВОЗРАСТ, СОЦИАЛЬНОЕ ПОЛОЖЕНИЕаа (2)
Особо отметим два интуитивных основания трактовки КФР в качестве базовой структуры кодирования. Во-первых, исследователь фиксирует с помощью этой модели не лобъект, существование или характеристики которого всегда могут быть оспорены другим человеком в силу известных трудностей лобъективного выражения субъективного смысла (А. Шюц), а факт изменения собственных понятий. Именно факт, т.к. термины в КФР указаны явно, в отличие от интуитивно постигаемых лобъектов, предполагаемых за каждым из аналитических обозначений. Такой факт наблюдается всеми реципиентами процесса кодирования, в то время как соответствие лобраза его аналитическому обозначению всегда остается внутри автора такого действия.
Во-вторых, структура КФР означает, что факт изменения понятий соотнесен с явно указанным обозначением. Иначе говоря, структуру КФР можно интуитивно понять, как обозначение условий, при которых осуществляется изменение терминов.
Совокупность терминов, вводимых аналитиком в процессе контекстно-ориентированного кодирования и связываемых им между собой с помощью множества КФР, названа тезаурусом. Обратим внимание, что, во-первых, термин, представленный в тезаурусе, может не входить ни в одно КФР. Такой термин игнорируется ниже описываемыми алгоритмами. Во-вторых, связи между терминами содержатся в тезаурусе только в виде структур КФР.
Интуитивный смысл тезауруса в том, что он включает в себя все изменения понятий, которые аналитик счел нужным указать для сведения его вновь формируемых терминов к общеизвестным представлениям.
Термин, входящий в состав тезауруса, считается контекстно определенным, если он является разъясняемым в составе хотя бы одного КФР. Термин t контекстно определен относительно термина t0, если t является целевым, а t0 контекстом в одном и том же КФР, например, t0:tо{ti}. Вышеупомянутый СОЦДЕМ в соответствии с формулой (2) является контекстно определенным понятием относительно контекста ИССЛЕДОВАНИЕ 2004.
Один и тот же термин может быть определен относительно нескольких контекстов. Такой термин назван поликонтекстным. Если термин является разъясняемым только в одном КФР тезауруса, то он именуется моноконтекстным.
Отметим, что контекстное определение термина с помощью КФР не зависит от состава пояснений, использованных в этом КФР. В частности, множество пояснений может быть пустым. Такое множество будем обозначать {Е}.
Алгоритм построения иерархии контекстов. Структуры связей между терминами таковы, что позволяют предложить алгоритм, способный агрегировать дескрипторы, принадлежащие различным КФР тезауруса на позиции контекста, в единую структуру соподчинения. Этот алгоритм строится на эвристическом правиле, устанавливающем наличие или отсутствие связи между двумя терминами, использованными в двух разных КФР на позиции контекста. Если структура двух КФР такова, как показано в формулаха (3) и (4), т.е. если один и тот же термин (t1) является контекстом в одном из них (КФР1), и он же служит разъясняемым (контекстно определен) в другом (КФР2), то t2 является контекстным обобщением t1 .
а КФР2 = t2:t1о{Е},а (4)
Поясним на примере неформальные основания введенного правила. Допустим, что аналитик создал два интуитивно понятных КФР. В первом он предложил рассматривать ДОМ в контексте УЛИЦА (5), т.е.
а УЛИЦА: ДОМо{Е}. (5)
Во втором тот же термин УЛИЦА разъяснен в контексте ГОРОД (6), т.е.
а ГОРОД: УЛИЦА о{Е}. а (6)
Другими словами, термин, использованный как контекст, сам оказывается разъясняемым в другом контексте.
Использование одного и того же термина УЛИЦА в разных позициях двух КФР является основанием считать, что контекст ГОРОД оказывается более общим по отношению к контексту УЛИЦА. Другими словами, ГОРОД является контекстным обобщением (расширением) УЛИЦА .
Такому суждению есть два интуитивных обоснования. Во-первых, термины УЛИЦА и ГОРОД употреблены как контексты. Во-вторых, будучи разъясненным в контексте ГОРОД, УЛИЦА, с точки зрения выполнившего такое разъяснение аналитика, составляет только часть тех феноменов или сюжетов, которые поименованы термином ГОРОД. Это утверждение может быть пояснено тем, что относительно одного и того же контекста всегда возможно определение неограниченного числа понятий. Например, КВАРТАЛ также может быть контекстно определен относительно термина ГОРОД.
В общем случае алгоритм построения контекстного обобщения исходит из заданного пользователем КФР, например, введенного с помощью формулы (7).
а t0:tо{Е},а (7)
На исходном нулевом шаге алгоритм находит в тезаурусе множество терминов, которые контекстно обобщают (включают в себя) t0. Обозначим это множество Y0={t0i}, i=0,...m0-1, где m0 - число контекстов, в которых введен t0. Если множество Y0 не пусто, то для каждого его элемента алгоритм строит множество контекстных обобщений, создавая тем самым совокупность множеств Y0i = {t0ij}, i=0,Е m0-1,j=0,...m0i-1, где m0i - число контекстов, в которых введен t0i.
Контекстное обобщение термина t0
юбой из последующих шагов приводит к разворачиванию каждого из элементов множества контекстных обобщений Y. , полученных на предыдущем шаге. Алгоритм прекращает свою работу, когда все множества контекстных обобщений, полученных на очередном шаге, оказываются пустыми. Результаты работы алгоритма представимы в виде графа типа река, фрагмент формирования которого показан на рис. 2.

В пакете соподчинение контекстных включений, порождаемое заданным контекстом, выражается отношениями родитель-дети в составе алгоритмически создаваемого графа. Этот граф назван иерархией контекстов. Для приведенного простейшего примера иерархия контекстов показана на рис. 3 (см. также рис. 7).
ГОРОД - контекстное обобщение термина УЛИЦА
Алгоритм связывания терминов. В диссертации предложен алгоритм, который позволяет на основе тезауруса и иерархии контекстов сгенерировать связи термина с другими терминами. Процесс такой генерации назван связыванием термина. Ее результат представим в виде графа типа дерево, названного терминологическим. Напомним, что любые алгоритмические операции проводятся в развиваемом подходе только с контекстно определенными дескрипторами. Поэтому в узле графа представлена пара терминов. Один элемент пары - дескриптор (понятие, актор или действие), другой - контекст его определения, также выраженный дескриптором.
Исходным шагом алгоритма является указание аналитиком термина t0, определенного в контексте t(c) и имеющего непустое множество пояснений, как показано в формуле (8):
t(c):t0о{t0i},аа (8)
где i=0,Е,n-1, n-1 - число пояснений, n>1.
При алгоритмическом построении терминологического графа иерархия контекстов термина t(c) предварительно автоматически генерируется с помощью вышеописанного алгоритма.
Дальнейшая работа алгоритма связывания сводится к известным методам построения древовидного графа за счет того, что структура каждого единичного перехода родитель-дети, автоматически извлекается из состава соответствующего КФР. Так, на исходном шаге строится корневой узел дерева, воспроизводящий родителя t0, а множество его пояснений {t0i} рассматривается как список потенциальных детей.
Ключевая особенность алгоритма по сравнению с указанными известными методами состоит в том, что множество пояснений, составленное аналитиком, не становится набором детей безусловно. Оно может быть модифицировано в зависимости от того, в каком отношении контекст каждого из пояснений находится с контекстом целевого термина.
Проблема, решаемая алгоритмом при формировании каждого перехода родитель-дети на основе КФР, существует уже на исходном шаге. В соответствии с высказанным выше замечанием каждый из терминов формулы (8) должен быть контекстно определенным. Если целевой термин t0 по (8) определен однозначно относительно t(c), то контекст любого из пояснений невозможно определить по этой формуле, т.к. он в ней не указан.
Для разрешения возникающей неопределенности алгоритм отыскивает по тезаурусу множество возможных контекстов каждого из пояснений t0i, т.е. строит {t0ik}, где k = 0,Е,m0i-1; m0i-1 - число контекстов, в которых определено пояснение, т.е. термин t0i. Если среди этих контекстов находится такой, который согласован (см. следующий абзац) с контекстом родителя, т.е. t(c), то t0i, включается в автоматически генерируемый список детей. В противном случае отклоняется.
В общем случае алгоритм связывания контекстно определенных терминов может использовать различные правила согласования контекстов. В существующей версии пакета для отработки всей инфраструктуры подхода используются два, которые автору представились самыми простыми. Во-первых, если пояснение не является контекстно определенным, то оно не включается в состав детей родителя, который генерируется из целевого термина при алгоритмическом расширении этого термина.
Во-вторых, если ни один контекст определения пояснения не входит в иерархию контекстов, предварительно построенную для контекста родителя, то такое пояснение не включается в состав детей, алгоритмически генерируемого отношения родитель-дети (результат работы алгоритма см. рис. 8).
Поясним особенность алгоритма агрегирования на интуитивно понятном примере. Пусть в уже упоминавшемся контексте УЛИЦА аналитик разъясняет термин ДОМ через четыре других термина следующим образом:
УЛИЦА: ДОМо СТЕНА, КРЫША, ФУНДАМЕНТ, ЖИТЕЛЬ а аа (9)
Причем контекстная определенность каждого из пояснений задается КФР, показанными в формулах 10-13, в частности, термин ЖИТЕЛЬ введен в состав тезауруса в контексте СТРАНА, который не входит в состав иерархии контекстов термина УЛИЦА (см. рис. 3).
ГОРОД: СТЕНАо{Е}а (10)
УЛИЦА: КРЫШАо{Е}а (11)
УЛИЦА: ФУНДАМЕНТо{Е} (12)
СТРАНА: ЖИТЕЛЬо{Е}аа (13)
В этом случае автоматически формируемый переход родитель-дети не будет включать термин ЖИТЕЛЬ (см. рис. 4).

Результат генерации единичного перехода родитель-дети для контекстно-фиксированного разъяснения термина ДОМ в контексте УЛИЦА с учетом контекстной определенности каждого из пояснений.
Аналитик вправе пополнить контекстное определение термина ЖИТЕЛЬ, сделав его поликонтекстным, например, добавив еще одно КФР, выраженное формулой (14):
ГОРОД: ЖИТЕЛЬо{Е}аа аа (14)
В этом случае список детей в соответствующем алгоритмически генерируемом единичном переходе изменится на тот, который показан на рис. 5.

Термин ЖИТЕЛЬ определен в двух контекстах, один из которых - ГОРОД - входит в иерархию контекстов термина УЛИЦА (рис. 2), а другой - СТРАНА - нет.
Контекстно-ориентированная концептуализация
Применительно к предметной области анализа качественных данных концептуализация может трактоваться как перевод потока сведений, сообщаемых информантом, в аналитические обозначения (коды), создаваемые аналитиком. В основе такой трактовки лежит методологическое допущение, возникшее в анализе нечисловой информации еще во времена карандаша и бумаги: фрагмент данных, полученных от информанта, считается фактологическим обоснованием кода, т.е. обозначения, вводимого социологом и не содержащимся в свидетельстве информанта.
Это допущение объясняет цель концептуализации, достижение которой возлагается на ее автора - продемонстрировать связь вновь создаваемых аналитических обозначений с существующими свидетельствами. Следуя традиции АКД, будем понимать под контекстно-ориентированной концептуализацией процесс связывания аналитиком (социологом) аналитических обозначений (дескрипторов), вводимых им самим, со свидетельствами информанта.
Для иллюстрации техники контекстно-ориентированных методов воспользуемся текстовым свидетельством молодого человека о плюсах и минусах совместного проживания с родителями, представленном на рис. 1.
В соответствии с требованием контекстно-ориентированного подхода поименуем весь комплекс суждений молодого человека - о его переживаниях, отношениях с родителями, обстоятельствах своего проживания с ними и т.п. - новым термином РАЗМЫШЛЕНИЯ И ПЕРЕЖИВАНИЯ ИНФОРМАНТА, с учетом условий, при которых мы рассматриваем размышления информанта, обозначив их как СВИДЕТЕЛЬСТВО ИНФОРМАНТА (СЮЖЕТ, КОНТЕКСТ).
Естественно считать терминологическую пару РАЗМЫШЛЕНИЯ И ПЕРЕЖИВАНИЯ ИНФОРМАНТА в контексте СВИДЕТЕЛЬСТВО ИНФОРМАНТА (СЮЖЕТ, КОНТЕКСТ) собственными исходными представлениями аналитика. Ввиду того, что такие представления формулируются единственным актором , они могут характеризоваться как несформированные или сугубо индивидуальные (лсубъективные) и подлежащими разъяснению.
Альтернативой собственным представлениям социолога в рамках концептуализации нечисловых данных служат термины, которые естественно назвать разделяемыми или общезначимыми, т.к. в силу самой процедуры кодирования они декларируются понятными как социологу, так и информанту. В традиционной схеме анализа нечисловой информации подобные общезначимые понятия возникают в отправной процедуре, называемой первичным (initial, иначе - открытым, open) кодированием. Первичные коды - это фактически аппарат лцитирования аналитиком информанта, за счет чего фрагмент текста оказывается конструктивно включенным в понимание как минимум двух лиц - информанта и аналитика.
Можно сказать, что первичные коды - это термины, интуитивно понятные некоторому кругу лиц. При этом число лиц, составляющих этот круг, в принципе не имеет значения, т.к. в основе процедуры лежит акт коммуникации акторов, осуществимый уже в случае двух человек, и не требующий представительной выборки [населения, экспертов и т.п.].
В контекстно-ориентированном АКД на аналитика наряду с формулированием собственных терминов ad hoc возлагается задача указания тех понятий, которые он считает общезначимыми . В случае анализируемого текста такими общезначимыми представлениями (лтерминами-цитатами, финальными понятиями) концептуализации оказываются, например, НЕ С КЕМ ПОГОВОРИТЬ, САМОСТОЯТЕЛЬНОЕ ПРОЖИВАНИЕ ИНФОРМАНТА и др., с которыми аналитик связал фрагменты текстового свидетельства информанта.
Теперь задачей автора концептуализации становится указание всех понятийных переходов от исходной пары терминов РАЗМЫШЛЕНИЯ И ПЕРЕЖИВАНИЯ ИНФОРМАНТА в контексте СВИДЕТЕЛЬСТВО ИНФОРМАНТА (СЮЖЕТ, КОНТЕКСТ) к терминам-цитатам. Решение этой задачи может быть условно представлено в виде следующих взаимосвязанных процедур. Во-первых, указание социологом областей сложившихся представлений (смысловых доменов), относительно которых он в ходе концептуализации определяет как свои термины, так и суждения информанта. Во-вторых, построение социологом всех изменений терминов, которые он считает необходимым выполнить для цели обоснования своих суждений. Результаты выполнения аналитиком этих процедур накапливаются в тезаурусе. В-третьих, генерация единых структур: а) иерархии контекстов, т.е. соподчинения указанных аналитиком смысловых доменов и б) терминологического графа, т.е. перехода от собственных терминов аналитика к свидетельству информанта. Генерация выполняется пакетом по запросу социолога на основе текущего состояния тезауруса.
Ориентиром в решении аналитиком задачи перехода с помощью контекстно-ориентированных методов является традиционная для АКД идея покрытия содержания свидетельства информанта с помощью вновь вводимых обозначений . Однако при таком покрытии чрезвычайно важно обеспечить не только полную представительность мнения информанта в аналитических выкладках социолога, но и воспроизвести скрытую структуру фактологических суждений с помощью явных отношений между терминами концептуализации .
Контекстно-ориентированные методы позволяют аналитику структурировать свои теоретические выкладки с помощью аппарата, который является аналогом отношений множественного наследования (multiple inheritance) и видимости (visibility), на которых основываются структурные связи между аналитическими обозначениями в языках программирования высокого уровня. Подобные методы доказали свою эффективность в бесчисленных приложениях, благодаря которым создано современное информационное общество.
По мнению автора, подобный аппарат отсутствует в сегодняшних компьютерных методах анализа нечисловой информации. Сравнивая же предлагаемые решения с аналогами, реализованными, например, в языках C++, Object-Oriented Pascal и др., можно отметить относительную простоту контекстно-ориентированного синтаксиса, с помощью которого вводятся отношения наследования и видимости.
Теперь поясним первую процедуру контекстно-ориентированной концептуализации - указание областей сложившихся представлений. Например, молодой человек что-то рассказывает о своих переживаниях в условиях совместного проживания с родителями. Прежде чем анализировать его рассказ, следует обозначить условия, при которых этот рассказ развертывается и концептуализируется. Таким образом в составе тезауруса появляется термин СОВМЕСТНОЕ С РОДИТЕЛЯМИ ПРОЖИВАНИЕ, который как раз и обозначает обстоятельства суждений информанта по поводу совместного проживания. Аналогично, на основе собственного прочтения свидетельстваа автор ввел термины САМОСТОЯТЕЛЬНОЕ ПРОЖИВАНИЕ ИНФОРМАНТА, ДЕЕСПОСОБНОСТЬ РОДИТЕЛЕЙ, МНОГО ЧИТАЮ и др. Эти понятия маркируют зоны смыслов, относительно которых определяются все другие термины, используемые при концептуализации.
Интуитивно понятно, что смысловые домены имеют некоторое соподчинение. Скажем, характеризуя ситуации, возникающие при совместном проживании с родителями, молодой человек может обращаться к общеупотребительной терминологии, используемой повсеместно и не требующей пояснений. К примеру, оценивающие высказывания хорошо, плохо и др.
В то же время обратное следует признать неверным: то, что понимаемо в рамках конкретного свидетельства информанта о своем проживании с родителями, теряет определенность вне этого свидетельства. Скажем, упоминание о спорах с отцом представляется информативным сообщением, характеризующим условия совместного проживания, и оказывается малозначащим вне такого контекста. Потеря информативности объясняется естественным образом. Словосочетание споры с отцом продолжает оставаться узнаваемым и в лобщих обстоятельствах, но теряются многие связи, важные для понимания анализируемых рассуждений: кто рассказывает, чей отец, какие условия проживания и многие другие коннотации, которые важны в конкретных ситуациях рассказа молодого человека.
Аналитик выражает подобные интуитивно обоснованные соподчинения в виде контекстного обобщения пары терминов, формируя это отношение по правилам, описанным выше. Вся совокупность созданных контекстных обобщений наряду с терминами, которые их составляют, накапливается в тезаурусе. Тезаурус, созданный в результате описываемой концептуализации, показан на рис. 6. Единая иерархия контекстов, выражающая соподчинение смысловых зон, формируется с помощью алгоритма (см. выше). Иерархия контекстов, построенная для данного случая, показана на рис. 7.
Создав иерархию контекстов, аналитик получает возможность приступить ко второй аналитической процедуре - выстраиванию совокупности изменений терминов, которые приводят от РАЗМЫШЛЕНИЯ И ПЕРЕЖИВАНИЯ ИНФОРМАНТА в контексте СВИДЕТЕЛЬСТВО ИНФОРМАНТА (СЮЖЕТ, КОНТЕКСТ) к финальным терминам концептуализации. Каждое из таких понятийных изменений можно представить как ответ на вопрос что такое?. Например, в качестве ответа на вопрос, что такое РАЗМЫШЛЕНИЯ И ПЕРЕЖИВАНИЯ ИНФОРМАНТА? автор нашел в тексте ряд суждений, которые обозначил терминами ПЕРЕЖИВАНИЯ ИНФОРМАНТА в контексте САМОСТОЯТЕЛЬНОЕ ПРОЖИВАНИЕ ИНФОРМАНТА, ПЕРЕЖИВАНИЯ ИНФОРМАНТА в контексте СПОРИТЬ С ОТЦОМ, УСТАЛОСТЬ в контексте МНОГО ЧИТАЮ и др.
Далее, каждый из терминов, возникший в качестве ответа на предыдущий вопрос что такое?, сам подвергается разъяснению. В соответствие с целью концептуализации этот процесс продолжается аналитиком до тех пор, пока ему не удастся связать свои исходные представления РАЗМЫШЛЕНИЯ И ПЕРЕЖИВАНИЯ ИНФОРМАНТА в контексте СВИДЕТЕЛЬСТВО ИНФОРМАНТА (СЮЖЕТ, КОНТЕКСТ) со всеми терминами-цитатами, которые он сам же предложил, читая текст информанта. Инструментально пошаговые ответы на вопросы что такое? создаются аналитиком с помощью КФР, где целевой термин является подлежащим, к которому обращен вопрос, а группа пояснений представляет собой ответ.
Пошаговое создание ответов на вопрос что такое? с помощью контекстно-ориентированных структур в точности повторяло бы построение традиционной иерархии кодов, широко используемой в классических функциях кодирования данных и представляющей собой граф типа дерево, если бы не контекстная определенность каждого термина. Особенность состоит в том, что нельзя разъяснить термин, определенный в более общем контексте через понятие, введенное в более низком контексте. Например, если ОЦЕНКА ПЛОХО введена в контексте ОБЩЕПРИНЯТЫЕ ПРЕДСТАВЛЕНИЯ, то ее нельзя разъяснить через термин НЕ С КЕМ ПОГОВОРИТЬ, если последний введен в более низком контексте САМОСТОЯТЕЛЬНОЕ ПРОЖИВАНИЕ ИНФОРМАНТА (см. рис. 5).
Тем самым перед аналитиком возникает необходимость постоянно сверять контекст очередного формулируемого суждения со смысловыми зонами, которые он сам ввел в качестве условий понимания собственных отдельных высказываний. В процессе такой работы человек вынужден постоянно отслеживать внутреннюю согласованность своих утверждений, возникающих в разных фазах развития собственной концепции.
В практической концептуализации одно и то же КФР используется как для разбивки на смысловые зоны, так и для ответа на вопрос что такое?. Наиболее полным итогом контекстно-ориентированной концептуализации является терминологический граф, который дает единое аналитическое представление свидетельств информанта с учетом областей смыслов, в которых эти свидетельства понимаются информантом с точки зрения аналитика. Соответствующий терминологический граф, демонстрирующий концептуальные связи в анализируемом текстовом свидетельстве показан на рис. 6. Узлом графа служит пара терминов. Первый - соответствующее пояснение в одном из КФР тезауруса, второй - понятие, которое использовано как контекст для этого пояснения.
В любой момент концептуализации, т.е. при любом составе формируемого тезауруса, аналитик имеет возможность видеть, за счет каких понятий и каких глобальных связей между ними осуществляется (не осуществляется) искомый переход от его терминов к свидетельству информанта.
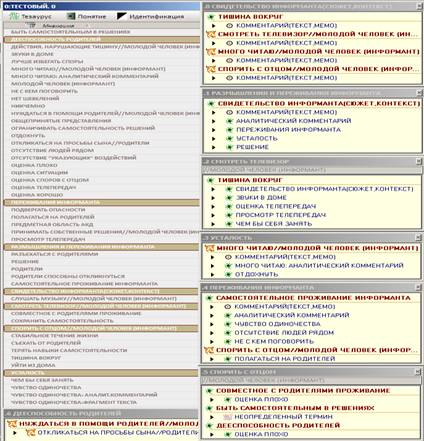
Визуализация тезауруса: слева (темный фон)- совокупность терминов, справа и внизу (светлый фон) - структурно разрозненные локальные отношения между терминами в виде контекстно-фиксированных разъяснений

Иерархия контекстов: узлами являются термины, использованные в КФР как контексты.
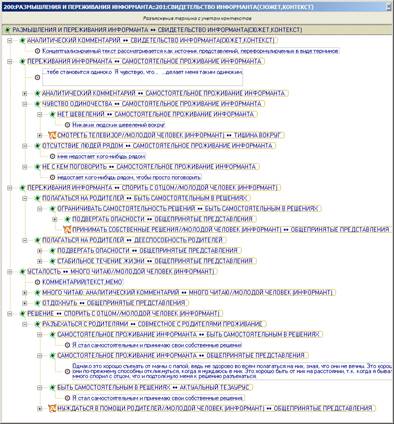
Терминологический граф, выражающий концептуализацию понятия РАЗМЫШЛЕНИЯ И ПЕРЕЖИВАНИЯ ИНФОРМАНТА при обстоятельствах, обозначенных термином СВИДЕТЕЛЬСТВО ИНФОРМАНТА (СЮЖЕТ, КОНТЕКСТ), согласно тезаурусу, показанному на рис. 6 .
В заключение подчеркнем, что инструментами, позволяющими контролировать ход и результаты концептуализации, выступают компьютерные средства генерации иерархии контекстов и терминологического графа. При этом находясь в условиях возможного автоматического контролирования своих концептуальных усилий на любой стадии их развертывания, аналитик побуждается к более ответственному формулированию собственных утверждений. Указанный способ концептуального контроля не зависит от аналитика и может быть выполнен любым реципиентом его теоретических построений.
ОСНОВНЫЕ НАУЧНЫЕ ПУБЛИКАЦИИ ПО ТЕМЕ ДИССЕРТАЦИОННОГО ИССЛЕДОВАНИЯ
Монография
- Каныгин Г.В. Контекстно-ориентированный подход к построению теорий: монография. - СПб: Норма, 2006. - 12,0 п.л.
Статьи, опубликованные в ведущих рецензируемых научных журналах, рекомендованных ВАК России:
- Каныгин Г.В. Поименование как инструмент конструирования социальных фактов // Научные проблемы гуманитарных исследований. - 2010. - №6. С. 156-163.Ц 0,6 п.л.
- Каныгин Г.В. Ненаблюдаемость социальных феноменов // Социологические исследования. - 2010. - №5. С. 26-33. - 1,0 п.л.
- Каныгин Г.В. Социологический метод в качестве источника социальной информации // Научные проблемы гуманитарных исследований. - 2008. - №5(16). С. 115-120. - 0,4 п.л.
- Каныгин Г.В. Контекстно-ориентированная концептуализация исследовательских понятий // Социологический журнал. - 2007. - №3. С. 59-80. - 1,0 п.л.
- Каныгин Г.В. Инструментальные средства и методологические принципы анализа качественных данных // Социология: методология, методы, математическое моделирование. - 2007. - № 25. С. 77-98.- 1,2 п.л.
- Каныгин Г.В. Конструируя конструктивизм // Социологические исследования. - 2006. - №11. С. 19-28. - 1,0 п.л.
- Каныгин Г.В. Данные в социологическом исследовании // Социологический журнал. - 2004. - №3/4. С. 27-46. - 1,0 п.л.
- Каныгин Г.В. Преобразование метафорического концепта в количественный объект // Социологический журнал. -2002. - №1. С. 60-74.- 1,0 п.л.
- Каныгин Г.В. Компьютерное ассистирование в массовых опросах: проблемно-ориентированный подход // Социологический журнал. -2001. - №2. С. 40-48. - 1,0 п.л.
- Каныгин Г.В. Базовые структуры анкетного метода // Социологический журнал. -1999. - №1/2. С. 143-155. - 1,0 п.л.
- Каныгин Г.В. Социологическое измерение и метафора // Социологический журнал. - 1998. - №1/2. С. 113-129. - 1,0 п.л.
- Каныгин Г.В. Предметная область при компьютерном моделировании анкетного опроса // Социологический журнал. - 1997. - №1/2. С. 93-119.-1,0 п.л.
- Каныгин Г.В. Пространство признаков и латентные измерения // Социологические исследования. - 1988. - №3. С. 105-112. - 1,0 п.л.
- Каныгин, Г.В., Мерсон А.Л. Комплексная оценка эффективности труда инженеров // Социологические исследования. -1983. -№1. С. 98-105.- 1,0 п.л. (авт. - 0,5 п.л.).
- Каныгин Г.В., Шкаратан О.И., Еремичева Г.В. и др. Характер внепроизводственной деятельности и социальная дифференциация горожан // Социологические исследования. - 1979. - №4. С. 104-110. -1,0 п.л. (авт. - 0,3 п.л.).
Статьи в профессиональных журналах и научных сборниках
- Каныгин Г.В. Проблемы анализа качественных данных // Экономика Северо-Запада: проблемы и перспективы развития. - 2007. - N1(31). С. 118-128. Ц 1,0 п.л.
- Каныгин Г.В. Текст как инструмент социального теоретизирования // Пути России: Проблемы социального познания / Под общ. ред. Д.М. Рогозина. - М.: Изд-во МВШСЭН, 2006. - 1,0 п.л.
- Каныгин Г.В. Компьютерное ассистирование в исследованиях региональной политики // Региональная политика. - 1992. -№1. С. 83-88. - 0,7 п.л.
- Каныгин Г.В., Перекрест В.Т. и др. Человеко-машинные методы анализа социально-экономических данных // Человеко-машинные системы обеспечения социально-экономических исследований. Л.: Наука, 1987. С. 92-135. 2 п.л. (-авт. 0,4 п.л.).
- Каныгин Г.В., Дьяконова О.Н., Заболотный А.М. и др. Система анализа социально-экономических данных. Часть 2. - Л.: Изд-во ИСЭП АН СССР, 1986. -52 с.- 2,0 п.л. (авт. - 0,4 п.л.).
- Каныгин Г.В., Коршунов А.М. Интеграционные процессы в полиэтнической городской общности. Опыт повторного исследования в городах Татарии // Этносоциальные проблемы города. / Ред. О.И.Шкаратан.- М.: Наука, 1986. - 1,0 п.л. (авт. - 0,5 п.л.).
- Каныгин Г.В., Перекрест В.Т., Сивашинский С.В. и др. Система анализа социально-экономических данных. Часть 1. - Л.: Изд-во ИСЭП АН СССР, 1985. -50 с. - 2,0 п.л. (авт. - 0,4 п.л.).
- Каныгин Г.В., Мерсон А.Л. Математическая модель структуры и факторов эффективности труда ИТР // Рабочий и инженер. Социальные факторы повышения эффективности труда. Ред. О.И. Шкаратан.- М.: Изд-во Мысль, 1985. С. 174-184.- 1,0 п.л. (авт. - 0,5 п.л.).
- Каныгин Г.В. Математическая модель структуры и факторов эффективности труда рабочих // Рабочий и инженер. Социальные факторы повышения эффективности труда. Ред. О.И. Шкаратан.- М.: Изд-во Мысль, 1985. С. 126-140. -1,0 п.л.
- Каныгин Г.В., Перекрест В.Т. Типологический анализ социально-экономических данных методами метрического шкалирования // Теоретические и методические проблемы построения базы социологических данных. - Вильнюс: Изд-во Ин-т философии, социологии и права АН ЛитССР. -1984. С. 170-187. (авт.- 0,5 п.л.)
Доклады на научных конференциях
- Каныгин Г.В. Контекстно-ориентированная концептуализация социологической информации //Компьютерная лингвистика и развитие семантического поиска в Интернете: Труды научного семинара XIII Всероссийской объединенной конференции Интернет и современное общество. Санкт-Петербург, 19-22 октября 2010 г. / Под ред. В.Ш. Рубашкина. - СПб., 2010. С. 30-41. -1,0 п.л.
- Каныгин Г.В. Анализ качественных данных - конструктивистская методология качественного исследования // Современная социология в поисках новых методологических подходов и методов исследования: Сборник научных материалов Всероссийской научной конференции, Самара, 16-17 мая 2008 года. - Самара: Изд-во Универс групп, 2008. С. 265-270.- 0,5 п.л.
- Kanyguine G.V. A Context-Oriented Approach in Design of Computer-Assisted Qualitative Data Analysis Software // Recent Developments and Applications In Social Research Methodology: Proceedings of the Sixth International Conference on Logic and Methodology, August 17-20, 2004, Amsterdam, The Netherlands. Edited by Cor van Dijkum, Jorg Blasius, Henk Kleijer, Branko van Hilten, 2004. (CD-ROM, ISBN 90-6706-176-x, SISWO). - 1,0 п.л.
- Kanyguine G.V. A Problem-oriented approach to a questionnaire design using CASI // Proceedings of the Fifth International Conference on Logic and Methodology October 3-6, 2000, Cologne, Germany. Edited by Jorg Blasius, Joop Hox, Edith de Leeuw, Peter Schmidt, 2000 (CD-ROM). - 1,0 п.л.
- Каныгин Г.В. Использование персональных компьютеров при изучении общественного мнения. Материалы Всесоюзной научной конференции Общественное мнение и политический процесс. - Л.: Изд-во ИСЭП. -1990. - 1,0 п.л.
Этим же словосочетанием названа процедура, основанная на описываемых правилах.
Будем считать множество пояснений пустым, т.к. его состав не важен для фиксации контекстной определенности целевого термина.
Можно также сказать, что УЛИЦА контекстно включен в ГОРОД.
Число позиций в определение индекса контекста зависит от шага алгоритма. В тексте этот индекс обозначен как жирная точка (.) и формируется индуктивным образом, который описан в диссертации.
в данном случае - диссертантом
В диссертации описан соответствующий структурный механизм, с помощью которого аналитик при посредстве пакета получает возможность выполнить такое указание.
Обычно это задача решается за счет первичного (открытого) кодирования.
В существующих методах АКД эта задача решается за счет концептуальных действий, надстроенных над процедурой первичного кодирования - осевого кодирования, введения категорий, аннотирования, естественноязыковых интерпретаций и др. При этом в случае применения компьютерного пакета широко используются лобщеинформационные методы - поиска, построения запросов, упорядочивания, визуализации и т.д.
В данном случае такого сорта терминология отнесена автором к контексту, обозначенному ОБЩЕПРИНЯТЫЕ ПРЕДСТАВЛЕНИЯ.
В смысле операции контекстного обобщения.
Указан через двойной знак умножения л**
Из-за недостатка места терминологический граф развернут не полностью.
В виду трудности адекватного и удобочитаемого перевода на русский язык этого термина современной социальной методологии в диссертации сохранен англоязычный оригинал.
Далее - просто функции, техники или аппарат кодирования.
Слово термин употребляется как синоним слова дескриптор в том случае, если не важен вид дескриптора - понятие, актор или действие. Подобная синонимия объясняется привычностью поименования термин или понятие для обозначения простейшей структурной единицы аналитических построений.
Здесь и далее экземпляры терминов, используемых в составе структурных моделей развиваемого подхода, обозначены с помощью заглавных букв.
Авторефераты по всем темам >>
Авторефераты по социологии