
 Все авторефераты докторских диссертаций
Все авторефераты докторских диссертаций
Метод распознавания символов, основанный на полиномиальной регрессии
Автореферат докторской диссертации
На правах рукописи
Пестрякова Надежда Владимировна
МЕТОД РАСПОЗНАВАНИЯ СИМВОЛОВ,
ОСНОВАННЫЙ НА ПОЛИНОМИАЛЬНОЙ РЕГРЕССИИ
Специальность 05.13.01 - Системный анализ, управление и обработка
информации (информационно-вычислительноеа обеспечение)
АВТОРЕФЕРАТ
на соискание ученой степени
доктора технических наук
Москва - 2012
![]() Работа выполнена в Федеральном государственном бюджетном учреждении науки
Работа выполнена в Федеральном государственном бюджетном учреждении науки
Институте системного анализа Российской академии наук в лаборатории 9-3 "Методы
искусственного интеллекта"
Научный консультант:а аа чллен-корреспондент РАН
Арлазаров Владимир Львович
Официальные оппоненты: доктор технических наук, профессор
Данилин Николай Семенович
доктор технических наук, профессор
Черешкин Дмитрий Семенович
доктор технических наук
Гаврилов Сергей Витальевич
Ведущая организация: а Федеральное государственное бюджетное учреждение науки
Институт проблем передачи информации им. А.А.Харкевича
Российской академии наук
Защита состоится 21 мая 2012 г. в 11.00 часов, аудитория 1506, на заседании
Диссертационного совета Д 002.086.02 апри Федеральном государственном бюджетном учреждении науки Институте системного анализа Российской академии наук по адресу Москва, проспект 60-лет октября, д. 9.
С диссертацией можно ознакомиться в библиотеке Федерального государственного бюджетного учреждения науки Института системного анализа Российской академии наук (Москва, проспект 60-лет октября, д. 9).
Отзывы на автореферат, заверенные печатью, просим направлять по адресу:
117312, Москва, проспект 60-лет октября, д. 9.
Автореферат разослан л___ __________ 2012 г.
Ученый секретарь диссертационного совета, д.т.н., профессор |
А.И. Пропой |
ОБЩАЯ ХАРАКТЕРИСТИКА РАБОТЫ
Актуальность темы. Задача распознавания печатных и рукопечатных символов весьма актуальна для различных видов современных наукоемких технологий, использующих оптический ввод документов. Рукопечатные символы - написанные от руки согласно стандартному начертанию букв (заглавные печатные буквы некоторого алфавита) и цифр.
Существующие классы распознающих систем (программы ввода текстов, системы потокового ввода структурированных документов, видеорегистраторы текстовых объектов) имеют различные стратегии распознавания, но опираются на общие алгоритмы распознавания символов.
С расширением области применения систем распознавания ужесточаются предъявляемые к ним требования. Это стимулирует разработку новых эффективных методов распознавания символов. Характеристики качества включают не только традиционные точность и быстродействие, но также свойства оценок распознавания, на основании которых определяется надежность алгоритмов более высокого уровня и всей системы в целом.
Появление и распространение технологий nVidia CUDA, ATI Stream, OpenCL и Microsoft DirectCompute порождает интерес к разработке методов, вычислительная структура которых удобна для распараллеливания.
Данная работа посвящена созданию обеспечивающих возможность распараллеливания эффективных приложений полиномиальной регрессии к задаче распознавания печатных и рукопечатных символов, обучению и проверке разработанного метода на различных базах символов (печатные прямые буквы и цифры, печатные прямые и курсивные цифры, рукопечатные цифры), теоретическому и численному анализу характеристик качества и свойств разработанного метода распознавания, а также разработке и реализации приложений метода распознавания в исследовании статистических свойств обучающих и распознаваемых множеств символов. В диссертации представлены все перечисленные направления.
Конкретные побудительные мотивы проведения исследований, представленных в диссертации, следующие.
1. Фундаментальной проблемой является разработка и программная реализация метода распознавания символов ввиду недоступности документации по существующим решениям. Открытые публикации содержат недостаточно информации для создания метода распознавания печатных и рукопечатных символов на основе полиномиальной регрессии.
2. В последние годы большое значение придается распараллеливанию численных алгоритмов с целью решения задач распознавания на многопроцессорной вычислительной технике. Особая эффективность метода, основанного на полиномиальной регрессии, определена тем, что решение исходной задачи легко сводится к решению серии более простых задач.
3. При разработке нового метода распознавания необходимо исследование свойств выставляемой им оценки для различных типов символов, а также сопоставление характеристик качества данного метода (быстродействие, точность распознавания, монотонность оценок) с другими известными методами.
4. Актуальным является изучение статистических свойств обучающих и распознаваемых множеств символов. Для этого годится далеко не каждый метод распознавания. В основе данного вероятностного метода распознавания лежит достоверно восстановленный неизвестный вероятностный закон, по которому распределены элементы обучающей последовательности символов, моделирующей датчик случайных векторов. Степень достоверности этого приближения соответствует точности распознавания на обучающем множестве. Ее высокий уровень позволяет использовать данный метод для анализа статистических свойств множеств символов.
Предметом исследований является:
1. Программная реализация методов распознавания печатных и рукопечатных символов; обучение и использование этих методов на различных базах символов (печатные прямые буквы и цифры, печатные прямые и курсивные цифры, рукопечатные цифры).
2. Теоретический и численный анализ характеристик качества и свойств разработанных методов распознавания.
Целями диссертации являются:
1. Разработка и реализация в виде библиотеки программ метода, основанного на полиномиальной регрессии, для численного решения задачи распознавания печатных и рукопечатных символов.
2. Численное исследование характеристик качества (быстродействие, точность распознавания, монотонность оценок) программной реализации метода на различных базах графических образов символов с известными границами (прямые печатные буквы и цифры, прямые и курсивные печатные цифры, рукопечатные цифры).
3. Сопоставление с характеристиками качества известных алгоритмов распознавания символов, таких как искусственные нейронные сети и алгоритм сравнения с эталонными образами.
4. Разработка методик и численные исследования на базах печатных и рукопечатных цифр:
- закономерностей в поведении оценок распознавания;
- особенностей взаимного расположения правильно, неправильно распознанных изображений символа, а также образов чужих символов (отличных от данного).
5. Разработка методик и численные исследования зависимости точности и оценок распознавания от степени различия между множествами обучения и распознавания.
Методология исследования. В работе был использован байесовский вероятностный прецедентный подход для задачи классификации на K непересекающихся классов. Ответом распознавателя считается K-мерный вектор вероятностей в принадлежности объекта к каждому из классов, по которому можно найти номер класса. Тем самым, классификация превращается в специальный случай регрессии, что отражено в названии работы.
Научная новизна заключается в следующем.
Введены новые величины (среднестатистический растр и полиномиальный вектор), являющиеся характеристиками множества изображений символов, и изучены особенности их распознавания. По разработанной методике в контексте этих величин найдены закономерности поведения средней оценки распознавания.
С использованием предложенного подхода на основе немонотонного поведения средней оценки распознавания изучена структура базы обучения.
Выполнено исследование механизма формирования средней оценки из оценок отдельных образов.
Найдены закономерности в расположении правильно, неправильно распознанных изображений символов, а также образов чужих символов.
Автор диссертации разработал методику и провел численные исследования зависимости точности и оценок распознавания от степени различия между обучающим множеством и полученной путем его модификации распознаваемым множеством для предложенных моделей затемнения - засветления и дискретизации. Установлены корреляционные соотношения с динамикой среднестатистических растров и векторов. Для рукопечатных и печатных цифр проведен сравнительный анализ полученных результатов.
Достоверность численных результатов проверена сопоставлением с данными, полученными аналитически.
Впервые введены понятия мелко-, средне- и крупномасштабных явлений при описании данного метода распознавания. Показано наличие организационных структур на средне- и крупномасштабном уровнях.
Практическая ценность и реализация результатов работы.
В диссертации разработан метод распознавания печатных и рукопечатных символов, основанный на полиномиальной регрессии. Выполнено обучение метода и проверка точности распознавания, быстродействия и монотонности оценок на базах печатных прямых букв и цифр, печатных прямых и курсивных цифр, рукопечатных цифр.
Проведенное в данной работе сравнение с другими методами распознавания символов, а также многолетняя практика использования метода показали, что разработанный и реализованный метод распознавания удовлетворяет высоким требованиям по точности распознавания, быстродействию, монотонности оценок. Метод хорошо зарекомендовал себя при распознавании сильно зашумленных (загрязненных и в значительной степени разрушенных) изображений.
Вычислительная структура метода обеспечивает возможность глубокого мелкозернистого распараллеливания. Это является неоспоримым преимуществом метода при распараллеливании как средствами CPU (центрального процессора), так и с помощью GPU (средств графических карт). Относительное увеличение скорости достигает 25 - 28 раз.
Разработанный алгоритм распознавания печатного и рукопечатного написания на базах графических символов с известными границами оформлен в виде библиотеки программ, состоящей из двух частей: обучение (с возможным дообучением) и распознавание для платформ Windows2000 / WindowsXP / Windows Vista / Windows 7.
Результаты диссертационной работы были использованы при реализации систем ввода документов в компьютер.
Данный метод в течение ряда лет применяется для распознавания рукопечатных цифровых реквизитов в системе массового ввода сложноструктурированных документов Cognitive Forms.
Высочайшая монотонность генерируемых оценок позволяет использовать метод в промышленной технологии тестирования распознавания печатных и рукопечатных документов как с известным заранее описанием структуры, так и без него. На этом основано его применение в алгоритмах адаптивного распознавания печатных символов на базе OCR Cuneifrom.
Апробация работы. Результаты диссертационной работы докладывались на семинарах ИСА РАН под рук. чл.-корр. РАН проф. В. Л. Арлазарова и д.т.н. проф. Н. Е. Емельянова, Международной научно-практической конференции Исследование, разработка и применение высоких технологий в промышленности (2009); Международной конференция Системный анализ и информационные технологии (2009, 2011); Международной научно-практической конференции Фундаментальные и прикладные исследование, разработка и применение высоких технологий в промышленности (2011); Международной конференции по Вычислительной механике и современным прикладным программным системам (2011).
ичный вклад автора. Основные научные результаты диссертационной работы принадлежат лично автору. Ряд экспериментальных данных получен при участии сотрудников Института системного анализа РАН. Автор являлся инициатором и исполнителем разработок, формулировал теоретические и экспериментальные задачи, намечал пути решения и решал их, разрабатывал и реализовывал методики исследований, разрабатывал программное обеспечение.
Положения, выносимые на защиту:
1. Новый вероятностный метод распознавания печатных и рукопечатных символов, основанный на полиномиальной регрессии, обладающий большим быстродействием, высокой точностью и монотонностью оценок, вычислительная структура которого обеспечивает возможность распараллеливания.
2. Способ представления полиномиальных векторов для печатных и рукопечатных символов.
3. Метод получения матрицы распознавания без обращения матрицы большой размерности.
4. Приложения метода распознавания в исследовании статистических свойств обучающих множеств символов.
5. Приложения метода распознавания в исследовании статистических свойств распознаваемых множеств символов.
По теме диссертации опубликовано 25 работ, в том числе 1 монография и 10 статей из Перечня рецензируемых научных изданий, рекомендованных ВАК РФ. Основные результаты диссертации представлены в публикациях, список которых приведен в конце автореферата.
Российский фонд фундаментальных исследований поддержал работы, определившие значительную часть содержания диссертации (грант РФФИ №10-07-0700374-а). Издана монография, обобщившая полученные результаты (грант РФФИ №11-07-07006-д).
Структура и объем работы. Диссертационная работа состоит из введения, четырех глав, заключения и списка литературы. Работа изложена на 257 страницах, содержит 48 иллюстраций и 29 таблиц. Библиография включает 192 наименования.
Во введении обоснована актуальность темы, сформулированы цель и задачи исследования, изложены структура и содержание диссертации.
В первой главе дано представление о распознавании образов - научной дисциплине, к которой относится выполненная работа. Приведены используемые в публикациях основные понятия и терминология. Рассмотрен байесовский вероятностный подход, лежащий в основе данного исследования, и описаны особенности его применения. Представлен обзор метрических алгоритмов классификации, к которым относится, в частности, метод сравнения с эталоном, используемый при сопоставлении с характеристиками качества метода, описанного в диссертации. Рассматривается задача восстановления регрессии и объяснено, что именно к ней сводится задача классификации в данной работе. Обсуждается проблема оценивания и выбора модели. Показано, что при разработке данного метода распознавания использовались как общепринятые, так и новые авторские подходы. Рассмотрены публикации по полиномиальным нейронным сетям. Основанный на этом подходе метод используется при сопоставлении с характеристиками качества метода, описанного в настоящей работе. Сформулированы выводы о том, как соотносятся результаты, полученные в диссертации, с публикациями по методам распознавания, а также о ее месте среди всего указанного спектра исследований в этой области.
Во второй главе рассмотрены теоретические основы и аспекты практической реализации разработанного метода. Производится сопоставление с известными алгоритмами распознавания символов.
Разработан алгоритм, позволяющий по предъявляемому растру изображения определить, какому символу из некоторого конечного множества с K элементами он соответствует. Представлением символа является растр, состоящий из N=N1?N2 серых или черно-белых пикселов. Перенумеровав все пикселы растра, запоминаем в i-ой компоненте (1?i?N) вектора vIRN состояние i-го пиксела (яркость), а именно, 0 или 1 в случае черно-белого растра и значение на отрезке [0,1] для серого растра. Пусть V={v} - совокупность всевозможных растров. Очевидно, VIRN, причем если пикселы черно-белые, то V={0,1}N - конечное множество, элементами которого являются последовательности из нулей и единиц длины N. Если пикселы серые, то V=[0,1]N - N-мерный единичный куб в RN.
Отождествим k-й символ с базисным вектором ek=(0Е1Е0)а (1 на k-м месте, 1?k?K) из RK. Обозначим Y={e1,Е,eK}.
Пусть для предъявляемого растра vIV можно найти pk(v) - вероятность того, что растр изображает символ с номером k, 1?k?K. Тогда результатом распознавания считается символ с порядковым номером ko, где
pko(v)=max pk(v),а 1?k?Kаа а (1)
Приближенные значения компонент (p1(v),Е,pK(v)) в соответствии с методом полиномиальной регрессии будем искать в виде многочленов от координат v=(v1,Е,vN):
pk(v) @ c![]() +
+ а+
а+ +Е, 1 ? k ? K. а(2)
+Е, 1 ? k ? K. а(2)
Суммы в (2) определяются выбором базисных мономов. Если
x(v)=(1,v1, Е ,vN, Е )T
конечный вектор размерности L из приведенных в (2) базисных мономов, упорядоченных определенным образом, то (2) можно записать так:
p(v) = (p1(v),Е,pK(v))T @ ATx(v) а(3)
Столбцами матрицыA размера L?K являются векторы а(1),Е, а(K). Каждый такой вектор составлен из коэффициентов при мономах соответствующей строки (2) с совпадающим индексомk, упорядоченных, как в x(v).
Пусть имеется датчик случайных векторов, распределенных по неизвестному нам закону p(v,y):
[v(1),y (1)], [v(2),y (2)],Еаа а (4)
Практически набор [v(1),y (1)],Е, [v(J),y (J)] реализуется некоторой базой данных. Приближенное значение А следующее (обучение):
аа А @ (![]()
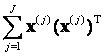 )-1(
)-1(![]()
 )а аа(5)
)а аа(5)
Правую часть (5) можно вычислить по рекуррентной процедуре:
Aj = Aj-1-ajGjx(j)[A![]() x(j)-y(j)]T, aj = 1/J
x(j)-y(j)]T, aj = 1/J
(6)
Gj = ![]() [Gj-1-aj
[Gj-1-aj ]аа 1?j?J
]аа 1?j?J
где А0 и G0 заданы. Введение матрицы Gj размера L?L апомогает избежать обращения матрицы в (5).
Разработанный автором метод полиномов - конкретная алгоритмическая реализация, основанная на описанном математическом подходе к решению задачи. Используется упрощенная модификация процедуры (6):
Gj? D-1, D = diag ( E{x![]() }, E{x
}, E{x![]() },Е, E{x
},Е, E{x![]() })а а аа(7)
})а а аа(7)
где x1, x2,Е,xL а- компоненты x(v). Масштабирование образов до размера растра N=256=16?16 сохраняет особенности геометрии символов (рис. 1).

Рис. 1 - Образы 16х16 печатных и рукопечатных символов
Достижением данного метода является конкретный вид вектора базисных мономов x(v). Его структура оптимизирована по точности распознавания символов обучающей выборки на базах графических образов (175 тыс. для рукопечатных цифр, 1 млн. символов для печатных букв и цифр). Используются два варианта вектора x. Длинный вектор имеет вид:
а x =(1, {vi}, {vi2}, {(dvi)r}, {(dvi)r2}, {(dvi)y}, {(dvi)y2},
{(dvi)r4}, {(dvi)y4}, {(dvi)r(dvi)y}, {(dvi)r2(dvi)y2}, {(dvi)r4(dvi)y4},
{(dvi)r((dvi)r)l}, {(dvi)y((dvi)y)l}, {(dvi)r((dvi)y)l}, а(8)
{(dvi)y((dvi)r)l}, {(dvi)r((dvi)r)d}, {(dvi)y((dvi)y)d},
{(dvi)r((dvi)y)d}, {(dvi)y((dvi)r)d})
Короткий вектор составлен из элементов в первой строке (8):
а х=(1, {vi}, {vi2}, {(dvi)r}, {(dvi)r2}, {(dvi)y}, {(dvi)y2}) (9)
Компоненты вектора x, не имеющие индекса l или d, вычисляются для всех пикселов растра; с индексом l - кроме левых граничных, с индексом d - кроме нижних граничных. Через (dvi)rа и (dvi)y обозначены конечные центральные разности величин vi по ортогональным направлениям ориентации растра - индексы r и y. Индекс l (left) или d (down) означает, что величины относятся к пикселу слева или снизу от данного. Вне растра vi=0. Поскольку рукопечатные символы имеют меньшую толщину, чем печатные, использовался прием искусственного луширения изображения.При вычислении элементов матрицы D(7) для каждого j-го элемента базы символов строится вектор x![]() согласно (8) или (9). Попутно рассчитываются компоненты вспомогательного вектора m
согласно (8) или (9). Попутно рассчитываются компоненты вспомогательного вектора m![]() по формуле:
по формуле:
m![]() а= (1-1/j) m
а= (1-1/j) m![]() + (x
+ (x![]() )
)![]() /j, j=1,Е,J, p=1,Е,Lа (10)
/j, j=1,Е,J, p=1,Е,Lа (10)
В конце этой процедуры для последнего элемента имеем согласно (7):
GJ ? D-1 = diag (1/m![]() ,1/m
,1/m![]() ,Е,1/m
,Е,1/m![]() )аа (11)
)аа (11)
После вычисления GJ для каждого j-го элемента базы символов строится вектор xj согласно (8) или (9) и находятся элементы матрицы Aj (5):
a![]() а= a
а= a![]() - ?j x
- ?j x![]() (
(![]() a
a![]() x
x![]() - y
- y![]() )/m
)/m![]() ,аа аа ?j = 1/J а(12)
,аа аа ?j = 1/J а(12)
A![]() а= [a
а= [a![]() ], j=1,Е,J, p = 1,Е,L , k = 1,Е,K
], j=1,Е,J, p = 1,Е,L , k = 1,Е,K
При распознавании по изображению строится вектор x согласно (8) или (9). Далее по формуле (4), используя A=AJ (12), вычисляются оценки для каждого из символов. Затем ищется символ с максимальной оценкой.
Получаемые из-за приближенности метода отрицательные оценки искусственно обнуляли, а превышающие единицу делали равными 1.
Далее используются целочисленные оценки 1, 2, Е, 16. После умножения оценки на 16 старый диапазон оценок [0,1] переходит в новый [0,16]. Затем проводится дискретизация: [0,1]>1, (1,2]>2, Е, (15,16]>16.
Анализируются следующие характеристики качества методов распознавания символов: точность, монотонность оценок и быстродействие.
Точностью распознавания по базе B называется величина
 а аа аа (13)
а аа аа (13)
где b - элементы тестовой базы образов B, | B | - число образов в базе B, C(b) - код символа, известный для каждого образа из тестовой базы,P(b) - код символа, полученный в результате распознавания, ?(s,t) - расстояние между известным и распознанным кодами символа (функция сравнения, равная 1, если s и t неразличимы, и равная 0 в противоположном случае). Коды прописных и строчных символов c одинаковым начертанием не различаются, например, группы букв кириллицы и цифр оО0 зЗ3 нН.
Используются следующие обозначения:N(W) - количество распознанных образов с оценкой W; NE(W) - число неправильно распознанных образов с оценкой W; v(W)=N(W)/|B| - частота распознавания с оценкой W; vE(W) = NE(W)/N(W) - частота ошибочного распознавания с оценкой W.
Монотонность оценок - свойство оценок характеризовать надежность распознавания. Исследуем совокупность частот {vE(WMIN), Е , vE(WMAX)}. Случаи с N(W)=0 не рассматриваем. Монотонность графика частот ошибок распознавания назовем монотонностью оценок метода. Интересны методы с монотонным убыванием в области высоких оценок.
Распределение оценок метода - совокупность частот {v(WMIN), Е , v(WMAX)} появления оценок. Для метода с монотонными оценками высокие оценки характеризуются большей надежностью распознавания, поэтому желательно, чтобы метод чаще распознавал образы с большими оценками.
Быстродействие - количество распознанных в единицу времени образов, зависящее от платформы. Ниже распознавание производилось с помощью библиотеки, собранной компилятором Microsoft Visual C++ 6.0 в режиме максимальной скорости исполнения с использованием инструкций SSE. Тесты проводились на платформе с ЦП Pentium IV 1500 МГц; 512 Мб ОЗУ; ОС Windows 2000).
На всех приведенных далее рисунках гистограммой обозначено распределение vE(W), а графиком - распределение v(W).
Для печатных прямых и курсивных цифр обучение проводилось на базе в 95 тыс. элементов с коротким вектором х. При обучении и распознавании между прямыми и курсивными символами не делалось различий. На тестовой последовательности из 12979 образов получена точность 0,9956, быстродействие а - а11500 образов/сек. Ошибок со старшими оценками (равными 14, 15 и 16) нет, доля этих оценок составляет 0,69 (рис.2).
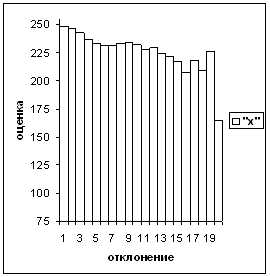
После обучения по базе в 175 тыс. рукопечатных цифр на тестовой последовательности из 8416 образов для длинного вектора х точность равняется 0,9973, а быстродействие Ца 4000 символов/сек (рис.3).


Рис. 2 - Печатные цифры аа Рис. 3 - Рукопечатные цифры
На этой же тестовой последовательности сопоставим характеристики метода полиномов, нейронной сети и метода сравнения с эталоном .
Для метода сравнения с эталонами размера 3х5 (рис.4) получена точность 0,9259, быстродействие Ца 8000 символов/сек. Для нейронной сети (рис.5) точность - 0,9976, а быстродействие Ца 4500 символов/сек.
Различие в точности распознавания нейронной сетью и полиномами, незначительное (0,9976 против 0,9973). Нейронная сеть распознает с максимальной оценкой 16 в 96,67% случаев, причем ошибается один раз, а полиномы - 34,2%, но без ошибок. Быстродействие методов сходно.
У метода сравнения с эталонами (рис.4) по отношению к методу полиномов намного ниже точность (0,9259 против 0,9973), заметно меньше доля максимальной оценки (0,0303 против 0,342) и хуже монотонность (больше частота ошибок для старших оценок).
Сравнение характеристик метода полиномов с алгоритмами распознавания символов другой природы показывает его конкурентоспособность в области генерации высокоточных монотонных оценок и быстродействия.
В третьей главе как обучение, так и распознавание проводилось на базе рукопечатных цифр из 174778 элементов. Целочисленные оценки 1, 2, Е, 255 получается из диапазона [0,1] аналогично оценкам 1, 2, Е, 16.


а Рис. 4 Ц Сравнение с эталонами 3х5аа Рис. 5 Ц Нейронная сеть
Зависимость средней оценки от отклонения между растрами изображений символа и его среднестатистическим растром качественно соответствует изображенной на рис.6а для л1 и рис.7а для остальных цифр, но уровень шумов существенно выше.
Для среднестатистического растра k-го символа яркость в любом пикселе с номером i равно среднему арифметическому значений яркости i-х пикселов по всем Jk имеющимся в базе растрам изображений символа:
 а аа(14)
а аа(14)
Расстояние между растрами v=(v1,Е,vN) иа u=(u1,Е,uN) определяем суммированием модулей разности значений яркости в i-х пикселах:
||v-u|| =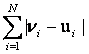 аа а(15)
аа а(15)
Отклонения между растрами распознанных верно изображений символа и его среднестатистическим растром находятся на отрезке [v_true_min, v_true_max] (35,41 ? v_true_min ? 50,76 и 101,70 ? v_true_max ? 173,80 для всех цифр).
Делим [v_true_min, v_true_max] (аналог оси абсцисс рис. 6а, 7а) на 20 равных частей. На каждом участке вычисляем среднюю оценку (ось ординат рис. 6а, 7а). Для л1 оценка монотонно убывает, затем увеличивается (велика зашумленность) до значения 255 на наибольшем удалении. Для остальных цифр есть тенденция к убыванию, но значителен шум.
Диаграмма числа правильно распознанных изображений из каждой части отрезка [v_true_min, v_true_max] для всех символов аналогична изображенной на рис.6б, 7б.
Для неправильно распознанных образов отклонения между растрами изображений символа и его среднестатистическим растром лежат на отрезке [v_false_min, v_false_max] (52,22 ? v_false_min ? 61,62 и 93,89 ? v_false_max ? 131,38). Неправильные оценки вдвое меньше правильных. Для каждого символа v_true_min < v_false_min, но диапазон [v_true_min, v_true_max] мало отличается от [v_false_min, v_false_max]. Поскольку доля ошибок низка, распределение количества изображений, распознанных как верно, так и неверно, схоже с результатами, полученными для правильного распознавания.
Зависимость средней оценки от отклонения между полиномиальными векторами х, построенными по растрам изображений символа, и его среднестатистическим вектором представлена на рис.6а для л1, а на рис.7а для л3 и аналогично для остальных цифр.
Для среднестатистического полиномиального вектора k-го символа значение в i-й компоненте равно среднему арифметическому i-х компонент векторов по всем Jk имеющимся в базе изображениям символа:
 аа(16)
аа(16)
Расстояние между векторами v=(v1,Е,vL) иа u=(u1,Е,uL) определяем как сумму по L компонентам модуля разности значений в i-х компонентах:
||v-u|| = а аа (17)
а аа (17)
Отклонения между полиномиальными векторами распознанных верно изображений символа и его среднестатистическим вектором лежит на отрезке [х_true_min, х_true_max] (2004 ? х_true_min ? 2798 и 4954 ? х_true_max ? 7917 для всех цифр).
 а
а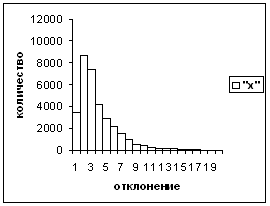
а)а б)
 а
а
в)а г)
 а
а
д)а е)
Рис. 6 - Поведение средней оценки - а), в), д) и количества образов -
б), г), е) при отклонении от среднестатистического вектора для л1
 а
а
а)а б)
Рис. 7 - Поведение средней оценки - а) и количества образов - б)
при отклонении от среднестатистического вектора для л3
Делим отрезок [х_true_min, х_true_max] (оси абсцисс на рис.6а, 7а) на 20 равных частей. Для изображений с полиномиальными векторами, попавшими в каждый такой участок, вычисляем среднюю оценку распознавания (оси ординат на рис. 6а, 7а). Для л1 она сначала убывает, а затем увеличивается до 255 на предпоследнем участке, а для остальных цифр убывает монотонно. Уровень шумов существенно ниже, чем для растров.
На рис.6б, 7б по оси ординат отложено число правильно распознанных изображений из каждой части отрезка [х_true_min, х_true_max] для символов л1 и л3 (по остальным цифрам - аналогично).
Отклонения между полиномиальными векторами неправильно распознанных изображений символа и среднестатистическим вектором этого символа находятся на отрезке [х_false_min, х_false_max]а (2913 ? х_false_min ? 3491 и 4909 ? х_false_max ? 6437). Для каждого символа х_true_min < х_false_min, но диапазон [х_true_min, х_true_max] отличается от [х_false_min, х_false_max] не очень существенно. Следовательно, поскольку доля ошибок мала, распределение числа образов, распознанных как верно, так и неверно, каждой из цифр схоже с рис.6б, 7б.
Чтобы сравнить поведение оценки в терминах растров и векторов, совместим отрезки [v_true_min, v_true_max] и [х_true_min, х_true_max]. Точке v_true соответствует х_true = х_true_min + (v_true - v_true_min)(х_true_max - х_true_min) / (v_true_max - v_true_min). Для символов, отличных от л1, до 1/2 или 1/3 величины максимального отклонения от 0 средняя оценка по векторам выше, чем по растрам. На отдаленных участках ситуация противоположная.
Особенное поведение оценки для л1 породило гипотезу, что база единиц составлена из двух подбаз. Чтобы выделить их, нашли изображения, чьи векторы удалены от х_true_min более чем на 2/3 величины х_true_max-х_true_min. По ним построили среднестатистическй вектор х1. Для этих 714 образам при отклонении от х1 оценка монотонно падает (рис.6д). По оставшимся 32388 изображениям построили среднестатистический вектор х2, при удалении от которого оценка также падает (рис.6в). Для этих подбаз распределения числа изображений (рис.6е, рис.6г) оказались схожими с распределениями для полных баз символов (рис.6б, 7б).
Для символа л8 показано, как монотонное убывание средней оценки распознавания при отклонении от среднестатистического вектора соотносится с распределениями числа верно распознанных изображений для различных оценок. Рассмотрены следующие диапазоны оценок: [255, 250), [250, 240), [240, 230), [230, 220), [220, 210), [210, 200), [200, 190), [190, 180), [180, 170), [170, 160), [160, 150), [150, 140), [140, 130), [130, 120). Изображений с более низкими оценками мало. На рис. 8а, б приведены распределения числа образов с оценками внутри диапазонов с более высокими оценками (для низких аналогично). На Рис.8а также показано распределение для всего спектра оценок [0, 255].
На каждой из частей отрезка [х_true_min, х_true_max] средняя оценка получается суммированием оценок 1, 2, 3, Е, 254, 255 с весами, определяемыми средней (по этой части) вероятности оценки. Монотонное убывание средней оценки соответствует наличию организационной структуры.
Среднестатистические растры и векторы распознаются правильно для всех символов. Любое изображение распознается как перечень из десяти альтернатив для каждого из символов с соответствующей оценкой. Альтернативы нумеруются по мере убывания оценок. Для правильно распознанного образа оценка 0ой альтернативы есть оценка распознавания. Соотношение между оценками 0ой и 1ой альтернативы говорит о контрастности распознавания (она тем больше, чем больше различаются оценки 0ой и 1ой альтернативы). Для каждой цифры оценка распознавания среднестатистического растра ниже, чем вектора. Оценка 1ой альтернативы для любого среднестатистического растра выше, чем оценка 1ой альтернативы среднестатистического вектора как того же символа, так и другого. Значит, среднестатистический растр любого символа имеет меньшую контрастность, чем среднестатистический вектор. Разброс оценок по всем символам при распознавании среднестатистических растров равен 229-105=124. Он намного выше, чем у векторов (240-219=21).

а) диапазоны [0, 255], [255, 250), [250, 240)

б) диапазоны [250, 240), [240, 230), [230, 220), [220, 210)
Рис. 8 - Число верно распознанных образов для различных оценок
символа л8.
Растры верно распознанных изображений любого символа могут находиться дальше от его среднестатистического растра, чем растры неверно распознанных образов (аналогично для полиномиальных векторов).
Среди верно распознанных изображений 87,50% растров наименее удалены от среднестатистического растра своего символа (для разных символов их доля варьируется в диапазоне 0,729 - 0,991). Аналогично, полиномиальные векторы 88,40% изображений наименее удалены от среднестатистического вектора своего символа (их доля 0,710 - 0,977).
Соответственно, среди неверно распознанных изображений всего лишь 53,35% растров наименее удалены от среднестатистического растра символа, получившего наивысшую оценку (для полиномиальных векторов 51,53% ). Причем не для каждого из символов их доля равна или превышает величину 0,5). Однако для векторов таких символов больше (9 против 7).
В четвертой главе как обучение, так и распознавание проводилось на одной и той же базе: для рукопечатных цифр - из 174778 элементов, а для печатных цифр - из 5496 элементов. Использовались оценки 1, 2, Е, 255.
Для печатных и рукопечатных символов построены диаграммы средней оценки распознавания в терминах растров (векторов) при делении отрезка [v_true_min, v_true_max] ([х_true_min, х_true_max]) на 5 равных частей с учетом малого объема базы печатных цифр по сравнению с рукопечатными.
Для печатных цифр диаграммы имеют общую тенденцию к убыванию (схожи с рис.7а), причем для растров (в отличие от векторов) высок уровень шумов. Для рукопечатных цифр уменьшение числа отрезков деления с 20 до 5 приводит к понижению уровня шумов для растров и векторов.
Распределения числа распознанных верно изображений в терминах растров (векторов) для печатных и рукопечатных цифр аналогичны.
Для обоих типов написания оценки неправильного распознавания значительно меньше, чем оценки правильного распознавания.Для любого рукопечатного символаv_true_min (x_true_min) меньше, чем v_false_min (x_false_min) любого другого или того же символа, а для печатных символов значительно меньше. При этом следует учесть, что для печатных символов распознано неверно лишь по два изображения для л1 и л3
Для произвольного символа G диапазон отклонений между растрами (векторами) изображений символов, отличных от G, и среднестатистическим растром (вектором) G по рассматриваемой базе находится от минимального мv_min до максимального мv_max (соответственно от мx_min до мx_max).
Для печатных цифр v_true_min (x_true_min) произвольного символа меньше, чем мv_min (мx_min) того же или какого-либо другого символа. Для рукопечатных цифр выполняется закономерность, являющаяся частным случаем приведенной: v_true_min (x_true_min) некоторого символа меньше, чем мv_min (мx_min) того же символа.
При рукопечатном написании для v_false_max (x_false_max) некоторого символа и мv_max (мx_max) произвольного символа имеем: v_false_max < мv_max (x_false_max < мx_max). Для печатных это также выполняется, но неправильно распознались лишь по два образа цифр л1 и л3.
Для любой рукопечатной цифры (кроме л1) при сравнении v_true_max (x_true_max) этого символа и мv_max (мx_max) того же самого или любого другого символа (включая л1) выполняется: v_true_max < мv_max (x_true_max < мx_max). Это выполняется и для каждого печатного символа.
Кроме того, для рукопечатных цифр каждая из трех минимальных величина v_true_min, v_false_min, мv_min (x_true_min, x_false_min, мx_min) некоторого символа меньше любой максимальной величины v_true_max, v_false_max, мv_max (x_true_max, x_false_max, мx_max) того же или какого-либо другого символа. Для печатных цифр выполняется закономерность, являющаяся частным случаем приведенной: каждая из трех минимальных величин v_true_min, v_false_min, мv_min (x_true_min, x_false_min, мx_min) некоторого символа меньше, чем любая максимальная величина v_true_max, v_false_max, мv_max (x_true_max, x_false_max, мx_max) того же символа.
Согласно полученным в диссертации результатам, для данного метода распознавания различаются мелко-, средне- и крупномасштабные явления.
К мелкомасштабным отнесены те, для которых не используется механизм осреднения (распознавание и выставление оценок образам символов).
При описании среднемасштабных используются среднестатистические растры и векторы, но не рассматривается механизм осреднения оценок (или он является несущественным). Сюда относится получение среднестатистического растра и вектора для каждого символа, относительно которых получают распределения числа образов того же символа для разных диапазонов оценок, а также местонахождение правильно, неправильно распознанных его изображений и чужих образов. На среднемасштабном уровне над хаосом мелкомасштабных явлений выявлена организационная структура - в расположении правильно, неправильно распознанных, а также чужих символов относительно среднестатистического вектора (растра).
Для крупномасштабных ключевыми являются ориентация на среднестатистический растр или вектор определенного символа и использование механизма осреднения оценок. Над хаосом мелкомасштабных и среднемасштабных явлений обнаруживается порядок. Несмотря на то, что на всем диапазоне отклонений от среднестатистического вектора имеются изображения данного символа с различными оценками, количество которых определяется полученным распределением, результат их коллективного действия - организационная структуры в виде монотонного уменьшения средней оценки при удалении от среднестатистического вектора (растра).
Интуитивно понятно, что любая база распознавания может быть получена из базы обучения, но неизвестен способ этого преобразования. В настоящей работе представляем базу распознавания как заданную модификацию базы обучения. Рассмотрены три модели: затемнения, засветления и дискретизации.
При затемнении на этапе распознавания все пикселы растра постепенно затемняются: vi > vi + 0,01 Х n, где n = 0, 1, .., 100. Если для каких-то пикселов начиная с некоторого n имеем: vi> 1, то считаем vi = 1. При засветлении vi > vi - 0,01 Х n, где n = 0, 1, ... , 100. Если получено vi< 0, то считаем vi= 0.
На рис.10 приведена зависимость от n доли (в процентном выражении) числа нераспознанных изображений относительно их общего числа (mis%t - затемнение, mis%s - засветление). Для рукопечатных цифр эта величина при затемнении растет монотонно, а при засветлении имеется немонотонность при 64 ? n ? 72. Для печатных mis%t и mis%s увеличиваются монотонно. Засветление печатных образов приводит к наименьшему нарастанию доли неправильно распознанных образов по сравнению с засветлением рукопечатных, а также затемнением и печатных, и рукопечатных символов: при n = 96 для печатных цифр mis%s = 2,4%, mis%t = 82,9%,а для рукопечатных mis%t = 81,0%, mis%s =а 46,1%.
Средняя оценка распознавания для рукопечатных символов и при затемнении (Prb_t), и при засветлении (Prb_s) сначала уменьшается, а затем увеличивается (рис.9). Для Prb_t средние темпы и падения, и ростаа в полтора-два раза выше, чем для Prb_s. Для печатных цифр Prb_s стремительно монотонно падает, а Prb_t при общей тенденции к гораздо более медленному монотонному уменьшению имеет небольшой участок немонотонности (локальный максимум при n = 80); здесь также нарушается гладкость для mis%t.
Cредняя оценка при n = 0 для печатных цифр несколько больше, чем для рукопечатных. Но при засветлении печатных изображений Prb_s резко падает. Prb_s при n > 0 меньше Prb_t для печатных, а при n = 3 становится ниже оценки засветления и при n = 12 - затемнения рукопечатных.
Зависимость от n расстояния между среднестатистическими растрами баз обучения и распознавания (vv_t - затемнение и vv_s - засветление) приведена на рис.12, а отклонения между среднестатистическими полиномиальными векторами (xx_t при затемнении и xx_s при засветлении) - на рис.11а,б
Для любого печатного или рукопечатного символа с ростом n увеличиваются vv_t и vv_s (рис.12). При 0 ? n ? 100 и для печатных, и для рукопечатных функции vv_t и vv_s гладкие и почти линейные, с замедлением роста (увеличивается число пикселов, в которых достигается значение яркости 1 при затемнении и 0 при засветлении). Они располагаются по возрастающей так: засветление (рукопечатные), засветление (печатные), затемнение (печатные), затемнение (рукопечатные). Для n > 0 величина vv_t превышает vv_s для рукопечатных цифр более чем вдвое, а для печатных - не более 15%.

Рис. 9 - Средняя оценка распознавания при затемнении и засветлении
С ростом n для рукопечатных xx_t строго растет, а xx_s при 64 ? n ? 72 немного падает (рис.11а). Для печатных xx_t и xx_s строго растут (рис.11б).
Аналогично vv_t и vv_s, для n > 0 величина xx_t более чем в полтора раза превосходит xx_sа для рукопечатных цифр, а для печатных их разница приближается к 20% лишь около n = 100.
График xx_s перестраивается при 64 ? n ? 72 (рис.11а). Здесь xx_s незначительно убывает, а левее и правее нарастает с почти постоянной скоростью, которая для n >72 в два раза ниже, чем для n < 64. На этом же отрезке перестраивается и график mis%s (рис.10). На этом участке mis%s незначительно убывает, а слева и справа монотонно увеличивается. Справа mis%s увеличивается с почти постоянной скоростью, котораяа ниже, чем соответствующая величина вблизи отрезка 64 ? n ? 72 слева. Итак, для n < 64 и n > 72 нарастанию xx_s соответствует увеличение mis%s, а при 64 ? n ? 72 очень незначительно убывают иа xx_s, иа mis%s. При 64 ? n ? 72 поведение Prb_s меняется от убывания к нарастанию: при n = 64 имеется минимум Prb_s (рис.9).
График xx_t (рис.11а) - монотонно возрастающий и кусочно-линейный. Производные рвутся при n = 24 и n = 32. На отрезке 24 ? n ? 32 темпы роста xx_t приблизительно втрое больше, чем левее и правее. Здесь же отрезке перестраивается график mis%t (рис.10); темпы роста mis%t выше, чем слева и справа. Итак, в диапазане 0 ? n ? 100 монотонно возрастают и xx_t, и mis%t. При 24 ? n ? 32 темпы их роста намного выше, чем на остальных участках. Именно при 24 ? n ? 32а поведение Prb_t коренным образом меняется от убывания к нарастанию: при n = 32 имеется минимум этой величины (рис.9).
аа 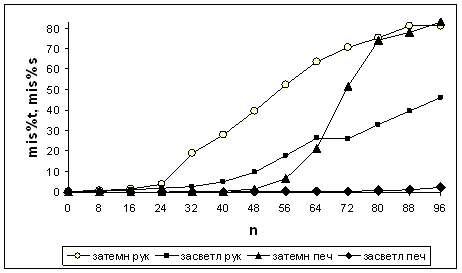
Рис. 10 - Доля нераспознанных растров при затемнении и засветлении
Структура вектора для печатных цифр более простая, чем для рукопечатных, но сложнее растрового представления. График оценки распознавания для печатных цифр имеет меньше особенностей, чем для рукопечатных (печатные: монотонное убывание для засветления и тенденция к этому для затемнения; рукопечатные: выраженная немонотонность (вогнутость) и для затемнения, и для засветления) - рис.9. Поведение доли нераспознанных изображений печатных символов также имеет меньше особенностей (печатные: почти монотонный рост, гладкость для засветления и нарушение ее лишь в одной точке для затемнения; рукопечатные: нарушение монотонности для засветления, большее нарушение гладкости для засветления и затемнения) - рис.10. В отличие от сложного рукопечатного вектора, графики отклонения среднестатистического простого печатного вектора, имеют меньше особенностей: являются гладкими, монотонными, - сходны с печатными и рукопечатными растровыми аналогами (рис.11а, б - рис.12). Как и последние, они не отражают проявлений немонотонности оценки и нарушения гладкости в графике доли нераспознанных символов (при затемнении печатного образа).
При полном затемнении с n = 100 (Черный квадрат) все рукопечатные изображения распознаются как л1 с оценкой 255. Этим и объясняется рост средней оценки Prb_t для n > 32 при затемнении. Однако при полном засветлении с n = 100 среди цифр от л0 до л9 нет столь уникально подходящей для Белого квадрата. В качестве решения выбираются различные цифры с существенно более низкими оценками, чем при полном затемнении.
Для печатных цифр при полном затемнении все образы, как и для рукопечатных, распознаются как л1, но с меньшей оценкой Prb_t = 93. Этим объясняется тенденция к монотонному убыванию Prb_t при затемнении. При полном засветлении все образы распознаются как л1 с минимальной оценкой Prb_s = 1, чем и объясняется монотонное убывание Prb_s.

а) рукопечатные цифры

б) печатные цифры
Рис. 11 - Расстояние между среднестатистическими векторами баз
обучения и распознавания при затемнении и засветлении
При n = 100 для рукопечатных цифр выполняются равенства: vv_t = 183,8, а также vv_s = 72,2. Следовательно, vv_t + vv_s = 256. Эта сумма соответствует расстоянию между растрами Белого и Черного квадратов. Отклонение среднестатистического растра базы обучения от растра Черного квадрата в два с половиной раза больше, чем от растра Белого квадрата. Поэтому vv_t превышает vv_s более чем в два раза для каждого n > 0.
Для печатных цифр при n = 100 выполняются равенства: vv_t = 136,6, а также vv_s = 119,4. Следовательно, vv_t + vv_s = 256 (расстояние между растрами Белого и Черного квадратов). Отклонение среднестатистического растра базы обучения от растра Черного квадрата приблизительно на 10% больше, чем от растра Белого квадрата (для рукопечатных символов - в два с половиной раза). Поэтому для печатных при n > 0 величина vv_t превышает vv_sа не более чем на 20% (а для рукопечатных - более чем в два раза).
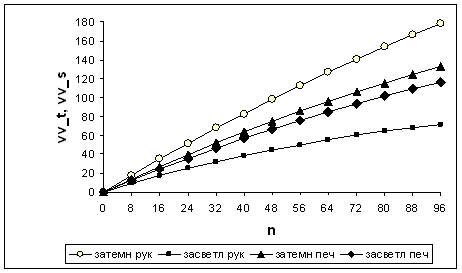
Рис. 12 - Расстояние между среднестатистическими растрами баз обучения и распознавания при затемнении и засветлении
Модель дискретизации - комбинация затемнения и засветления. В серых растрах яркость для каждого пиксела 0 ? vi ? 1. Поделим отрезок [0, 1] на 256 равных частей - отрезок и 255 полуинтервалов: [0, dv], (dv, 2 Х dv], Е , (255 Х dv, 256 Х dv], где dv = 1/256. Сделаем для всех пикселов растра преобразование: если 0 ? vi? dv, то vi > dv/2 (иначе [0, dv] > dv/2); в полуинтервале kХdv < vi? (k+1) Х dv, где k = 1, Е, 255, заменяем: vi > (k + 1/2) Х dv а(иначе (k Х dv, (k + 1) Х dv] > (k + 1/2) Х dv ). Это дискретизация бесконечного множества значений 0 ? vi ? 1, в результате vi может принимать 256 значений:а {dv/2, (1 + 1/2) Х dv,Е, (255 + 1/2) Х dv}. Полученная база мало отличается от исходной.
При дискретизации с количеством отрезков дискретизации Nдискр = 128, 64, 32, 16, 8, 4 каждая последующая база все больше отличается от исходной.
Для заданного Nдискр аналитически получено, какое максимальное n может быть в рамках моделей затемнения и засветления: n ? 50/Nдискр.
Для произвольного символа уменьшение Nдискр сопровождается увеличением расстояния между среднестатистическими растрами в базах обучения и распознавания vv (рис.15). В терминах среднестатистических полиномиальных векторов для xx сохраняется эта закономерность (аналогично рис.15). Темпы роста vv и xx, незначительные вблизи Nдискр = 256,а нарастают с уменьшением Nдискра - графики являются вогнутыми.

Рис. 13 - Средняя оценка распознавания при дискретизации
На рис. 13 - 15 расстояния на оси абсцисс не соответствуют меткам делений - цифрам 256, 128, 64, 32, 16, 8, 4, которые образуют убывающую геометрическую прогрессию с коэффициентом ?. Для того чтобы установить это соответствие, следует длину отрезка [128, 64] сделать в два раза меньше, чем для отрезка [256, 128], длину отрезка [64, 32] сделать в два раза меньше, чем для отрезка [128, 64] и т.д. Это аналогично сжатию вдоль этой оси фрагментов графиков для каждого последующего отрезка по сравнению с предыдущим в два раза. При этом графики станут еще более крутыми.

Рис. 14 - Доля нераспознанных растров при дискретизации
Можно заменить метки делений Nдискр на их предельные степени затемнения / засветления, а именно, fдискр = 50/Nдискр . Расстояния на оси абсцисс не будут соответствовать новым меткам делений - числам 50/256, 50/128, 50/64, 50/32, 50/16, 50/4, которые образуют возрастающую геометрическую прогрессию с коэффициентом 2. Чтобы установить это соответствие, следует длину отрезка [50/128, 50/64] сделать в два раза больше, чем для отрезка [50/256, 50/128], длину отрезка [50/64, 50/32] сделать в два раза больше, чем для отрезка [50/128, 50/64] и т.д. Это соответствует растяжению вдоль этой оси фрагментов графиков для каждого отрезка по сравнению с предыдущим в два раза. Графики станут более пологими и схожими с аналогами при затемнении и засветлении.
Анализ проводился для шкалы, изображенной на рис. 13 - 15. Для линейной по Nдискр шкалы он качественно не изменится, а скорости или темпы роста, о которых будет говориться далее, увеличатся.

Рис. 15 - Расстояние между среднестатистическими растрами
баз обучения и распознавания при дискретизации
Рост (с ускорением) vv (рис.15) и xx (аналогично рис.15) при уменьшении Nдискр соответствует уменьшению средней оценки распознавания Prb (рис.13), причем темпы убывания последней также увеличиваются с уменьшением Nдискр. И темпы роста vv, и темпы падения Prb для печатных выше, чем для рукопечатных. Доля неправильно распознанных символов mis% для рукопечатных (рис.14) с уменьшением Nдискр от 256 до 128 - очень незначительно увеличивается, от 128 до 64 - уменьшается, а при дальнейшем падении Nдискр от 64 до 4 - увеличивается с нарастающими темпами, а для печатных mis% неизменно при Nдискр от 256 до 16, а далее нарастает с постоянной скоростью (рис.14). Для рукопечатных цифр mis% и темпы ее роста больше, чем для печатных. И для печатных, и для рукопечатных графики изменения Prb и mis% при дискретизации с уменьшением Nдискр (Nдискр = 256, 128, 64, 32, 16, 8, 4) качественно соответствуют аналогичным для затемнения и засветления с 0 ? n ? 50/4.
Для рукопечатных mis достигает минимума при Nдискр = 64, для которого fдискр = 0,8. Ограничение на степени затемнения / засветления: n ? 0,8. При n = 1 для засветления также зафиксирован близкий по значению минимум mis.
При любом написании отклонение между среднестатистическими растрами (векторами) баз обучения и распознавания, количество нераспознанных символов и средняя оценка лежат в диапазоне между соответствующими результатами для затемнения и засветления при степени n=fдискр или близки к ним.
В заключении перечислены основные теоретические и практические результаты, полученные в рамках диссертационной работы, состоящие в следующем:
1. Разработан и реализован новый вероятностный метод распознавания печатных и рукопечатных символов, основанный на полиномиальной регрессии, обладающий большим быстродействием, высокой точностью и монотонностью оценок, вычислительная структура которого обеспечивает возможность распараллеливания.
2. Предложен и реализован способ представления полиномиальных векторов для печатных и рукопечатных символов.
3. Реализован метод получения матрицы распознавания без обращения матрицы большой размерности.
4. Разработаны и реализованы приложения метода распознавания в исследовании статистических свойств обучающих множеств символов.
5. Разработаны и реализованы приложения метода распознавания в исследовании статистических свойств распознаваемых множеств символов.
ОСНОВНЫЕ ПОЛОЖЕНИЯ ДИССЕРТАЦИИ ИЗЛОЖЕНЫ В СЛЕДУЮЩИХ РАБОТАХ:
Публикации в научных изданиях, рекомендованных ВАК
1. Гавриков М.Б., Пестрякова Н.В., Усков А.В., Фарсобина В.В. Оценка распознавания символов для метода, основанного на полиномиальной регрессии, // "Обработка изображений и анализ данных": сборник "Труды Института системного анализа Российской академии наук (ИСА РАН)" / под ред. В.Л. Арлазарова, Н.Е. Емельянова. Т.38.-а М.: Книжный дом "ЛИБРОКОМ", 2008. С.194-219.
2. Пестрякова Н.В. Структуры в распознавании. // Информационные технологии и вычислительные системы. 2009, №1, С. 58-71.
3. Пестрякова Н.В. Распознавание последовательности, полученной дискретизацией обучающей базы // "Обработка информационных и графических ресурсов": сборник "Труды Института системного анализа Российской академии наук (ИСА РАН) " / под ред. В.Л. Арлазарова. Т.58 - М.: "КРАСАНД", 2010. С. 226-237.
4. Пестрякова Н.В. Особенности распознавания печатных и рукопечатных символов, // "Технологии программирования и хранения данных": Сборник "Труды Института системного анализа Российской академии наук (ИСА РАН) " / под ред. В.Л. Арлазарова, Н.Е. Емельянова. Т.45.-а М.: "ЛЕНАРД", 2009. С. 206-230.
5. Гавриков М.Б., Мисюрев А.В., Пестрякова Н.В., Славин О.А. Об одном методе распознавания символов, основанном на полиномиальной регрессии. // Автоматика и Телемеханика. 2006, №2, С. 119-134.
6. Гавриков М.Б., Пестрякова Н.В., Усков А.В., Фарсобина В.В. Зависимость точности и оценки распознания от степениа различия между базами обучения и распознавания, // "Обработка изображений и анализ данных": сборник "Труды Института системного анализа Российской академии наук (ИСА РАН) "/ под ред. В.Л. Арлазарова, Н.Е. Емельянова. Т.38.-а М.: Книжный дом "ЛИБРОКОМ", 2008. С.233-240.
7. Пестрякова Н.В. Интегральные и дифференциальные характеристики базы символов // "Обработка информационных и графических ресурсов": сборник "Труды Института системного анализа Российской академии наук (ИСА РАН) " / под ред. В.Л. Арлазарова. Т.58 - М.: "КРАСАНД", 2010. С. 211-225.
8. Пестрякова Н.В. Динамика качества распознавания при нарастании степени различия баз обучения и распознавания. // Информационные технологии и вычислительные системы. 2010, №2, С. 75-82.
9. Пестрякова Н.В. Зависимость качества распознавания от степениа различия между базами обучения и распознавания, // "Технологии программирования и хранения данных": сборник "Труды Института системного анализа Российской академии наук (ИСА РАН)" / под ред. В.Л. Арлазарова, Н.Е. Емельянова. Т.45.-а М.: "ЛЕНАРД", 2009. С. 231-250.
10. Гавриков М.Б., Пестрякова Н.В., Усков А.В., Фарсобина В.В. О среднестатистических растрах и вектораха метода распознавания символов, основанного на полиномиальной регрессии, // "Обработка изображений и анализ данных": сборник "Труды Института системного анализа Российской академии наук (ИСА РАН)" / под ред. В.Л. Арлазарова, Н.Е. Емельянова. Т.38.-а М.: Книжный дом "ЛИБРОКОМ", 2008. С.220-232.
Монографии
11. Пестрякова Н.В.. Метод распознавания символов, основанный на полиномиальной регрессии. //М.: "КРАСАНД", 2011. 144с.
Статьи и материалы конференций, публикации в других изданиях
12. Пестрякова Н.В. Об оценках распознавания символов методом, основанным на полиномиальной регрессии, // Третья Международная конференция "Системный анализ и информационные технологии" САИТ - 2009 (14 - 18 сентября 2009 г., Звенигород, Россия):а Труды конференции. М., 2009. С. 62.
13. Пестрякова Н.В. Метод распознавания символов, основанный на полиномиальной регрессии // "Высокие технологии, фундаментальные исследования, образование": Сборник трудов Седьмой международной научно-практической конференции "Исследование, разработка и применение высоких технологий в промышленности". 28-30.04.2009, Санкт-Петербург, Россия / под ред.А.П. Кудинова, Г.Г. Матвиенко.- СПб. Изд-во Политехн. ун-та, 2009. С.129-130.
14. Пестрякова Н.В., Фарсобина В.В. Об оценках распознавания символов // "Высокие технологии, образование, промышленность": Сборник статей Одиннадцатой международной научно-практической конференции "Фундаментальные и прикладные исследование, разработка и применение высоких технологий в промышленности", Т.2. 17-29 апреля 2011 года, Санкт-Петербург, Россия /а под ред.А.П. Кудинова.- СПб. Изд-во Политехн. ун-та, 2011. С.101-102.
15. Пестрякова Н.В. Об одном вероятностном методе распознавания символов // Материалы XVII Международной конференции по вычислительной механике и современным прикладным программным системам (ВМСППСТ2011,. 25-31 мая 2011 г., Алушта.) - М., Изд-во МАИ-ПРИНТ, 2011. С.211-213.
16. Пестрякова Н.В., Фарсобина В.В. О некоторых закономерностях в распознавании символов // Труды Четвертой Международной конференции Системный анализ и информационные технологии (САИТ - 2011, 17- 23 августа 2011г., Абзаково, Россия). Т.2.- Челябинск. Изд-во Челябинского государственного университета, 2011. С.190 - 193.
17. Гавриков М.Б., Пестрякова Н. В. Метод полиномиальной регрессии в задачах распознавания печатных и рукопечатных символов, //Препринт ИПМатем. АН СССР, М., 2004, №22, 12 стр.
18. Гавриков М.Б., Пестрякова Н.В., Славин О.А., Фарсобина В.В. Развитие метода полиномиальной регрессии и его практическое применение в задачах распознавания, //Препринт ИПМатем. РАН, М., 2006, №25, 21 стр.
19. Гавриков М.Б., Пестрякова Н.В., Усков А.В., Фарсобина В.В. О некоторых свойствах метода распознавания символов, основанного на полиномиальной регрессии, //Препринт ИПМатем. РАН, М., 2007, №69, 20 стр.
20. Гавриков М.Б., Пестрякова Н.В., Усков А.В., Фарсобина В.В. О некоторых свойствах оценки метода распознавания символов, основанного на полиномиальной регрессии, //Препринт ИПМатем. РАН, М., 2008, №7, 28 стр.
21. Гавриков М.Б., Пестрякова Н.В., Усков А.В., Фарсобина В.В. Анализ метода распознавания символов, основанного на полиномиальной регрессии, //Препринт ИПМатем. РАН, М., 2008, №25, 28 стр.
22. Гавриков М.Б., Пестрякова Н.В., Усков А.В., Фарсобина В.В. Зависимость качества распознавания от взаимного расположения среднестатистических растров и векторов баз обучения и распознавания, //Препринт ИПМатем. РАН, М., 2009, №19, 28 стр.
23. Гавриков М.Б., Пестрякова Н.В., Усков А.В., Фарсобина В.В. Об оценках распознавания и структуреа расположения изображений символов, //Препринт ИПМатем. РАН, М., 2009, №49, 28 стр.
24. Гавриков М.Б., Пестрякова Н.В., Усков А.В., Фарсобина В.В. О распознавании модифицированной обучающей базы. (Часть 1), //Препринт ИПМатем. РАН, М., 2010, №9, 28стр.
25. Гавриков М.Б., Пестрякова Н.В., Усков А.В., Фарсобина В.В. О распознавании модифицированной обучающей базы. (Часть 2), //Препринт ИПМатем. РАН, М., 2010, №13,а 16стр.
Мисюрев А.В. Использование искусственных нейронных сетей для распознавания рукопечатных символов // Сборник трудов ИСА РАН Интеллектуальные технологии ввода и обработки информации, 1998, с. 122-127
13.Cавин О.А., Корольков Г.В., Болотин П.В. Методы распознавания грубых объектов // Сборник трудов ИСА РАН Развитие безбумажных технологий в организационных системах, 1999, с. 331-355.
Schurmann J. Pattern Сlassification,а John Wiley&Sons, Inc., New York, NY, 1996.
Все авторефераты докторских диссертаций